SVM处理非线性问题
我们在 机器学习笔记八之多项式回归、拟合程度、模型泛化 中讲过线性回归通过多项式回归方法处理非线性问题,同样SVM也可以使用多项式方法处理非线性问题。
import numpy as np |
我们可以使用datasets提供的make_moons()函数生成非线性数据,默认为100行2列的矩阵,既100个样本数据,每个样本数据2个特征。可以使用n_samples参数指定样本数据数量。我们将其绘制出来看看:
plt.scatter(X[y==0, 0], X[y==0, 1]) |
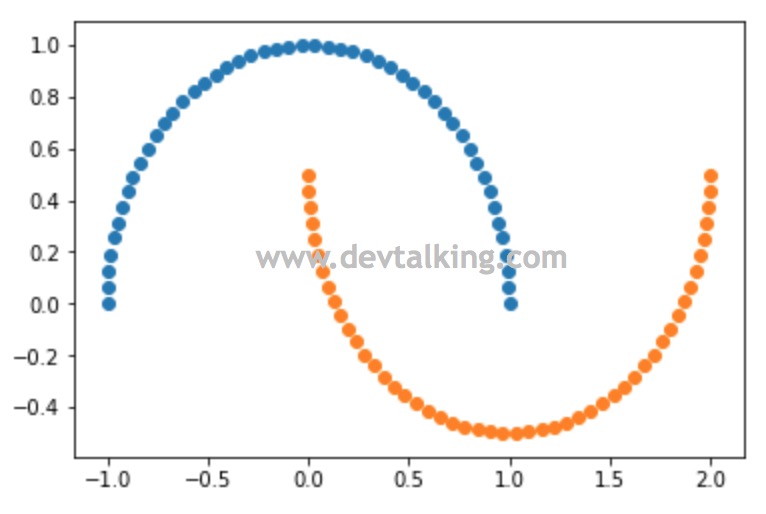
可以看到make_moons()默认生成的数据绘制出的图像是两个规整的半月牙曲线。但是作为样本数据有点太规整了,所以我们可以使用noise参数给生成的数据增加一点噪音:
X, y = datasets.make_moons(noise=0.15) |
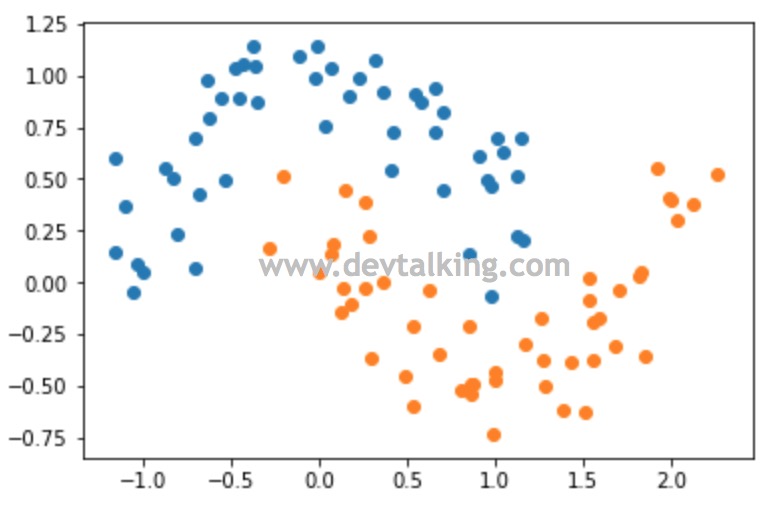
可以看到,增加了噪音后虽然数据点较之前的分布分散随机了许多,但整体仍然是两个半月牙形状。下面我们就在SVM的基础上使用多项式来看看对这个样本数据决策边界的计算:
from sklearn.preprocessing import PolynomialFeatures, StandardScaler |
首先我们需要引入我们用到的几个类:
- 多项式自然要用到之前讲过的
PolynomialFeatures类。 - 数据归一化需要用到
StandardScaler类。 - 同样需要用到Pipeline将多个过程封装在一个函数里,所以要用到
Pipeline类。