机器学习算法中有一个重要环节就是评判算法的好坏,我们在之间的笔记中讲过多种评价回归算法的评测标准,比如均方误差(MSE)、均方根误差(RMSE)、平均绝对误差(MAE)、$R^2$(R Squared)。但是在分类问题中我们一直使用分类准确度这一个指标,也就是预测对分类的样本数量除以总预测样本数量。但是这个方法存在很大的一个缺陷,所以这篇笔记主要介绍评价分类问题的方式方法。
极度偏斜数据(Skewed Data)
为什么说分类准确度这个指标存在很大的一个缺陷呢。举个例子,假设有一个癌症预测系统,输入体检信息,判断是否患有癌症。我们知道世界上相对于其他病症,患癌症的比例还是很小,如果癌症产生的概率只有0.1%,那么有99.9%的人都不会患有癌症。这就意味着,就算癌症预测系统什么都不做,但凡有体检信息输入,就给出没有患癌症的结果,那准确率也是达到了99.9%。那此时这个分类准确度是真实的吗?所以当样本数据或领域的实际情况存在数据极度偏斜的时候,只使用分类准确度这个指标是远远不够的。
混淆矩阵(Confusion Matrix)
这一节介绍一个能进一步分析分类结果的工具,混淆矩阵。
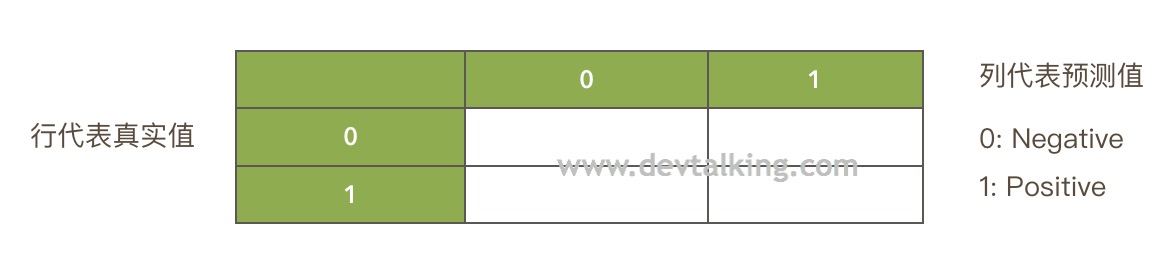
上面这个表针对二分类问题,所有将类别就分为两类0和1,0表示Negative,类似医院上的阴性,1表示Positive,类似医学上的阳性。行代表真实值,列代表预测值。
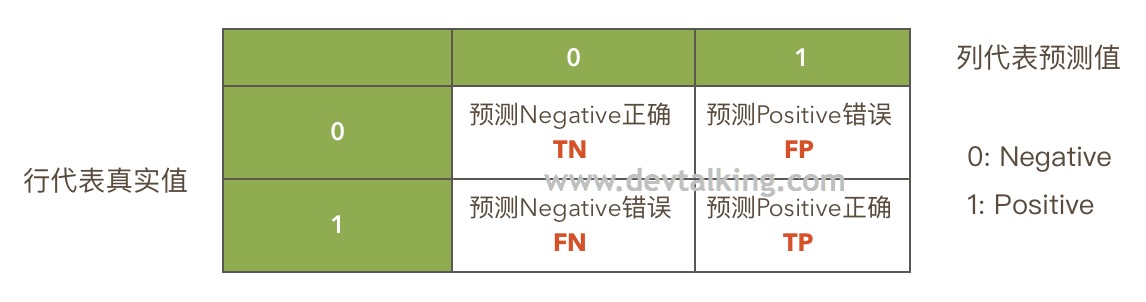
如上图所示:
- (0, 0)格子真实值和预测值都为0,称为预测Negative正确,记作True Negative,简写为TN。
- (0, 1)格子真实值为0,但预测值为1,称为预测Positive错误,记作False Positive,简写为FP。
- (1, 0)格子真实值为1, 但预测值为0,称为预测Negative错误,记作False Negative,简写为FN。
- (1, 1)格子真实值和预测值都为1,称为预测Positive正确,记作True Positive,简写为TP。
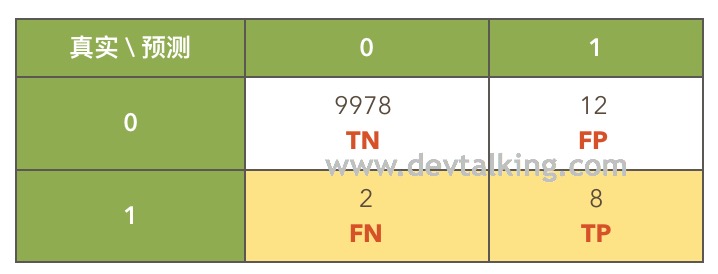
以上这个表格就叫做混淆矩阵。举个例子,如果对10000个人预测他们是否患癌症,通过混淆矩阵表示出的真实情况就是:
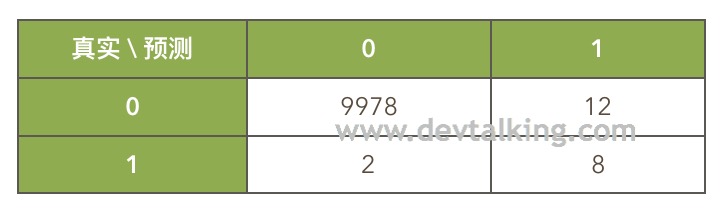
解读一下:
- 没有患癌症,系统也预测出没有患癌症的人为9978人(TN)。
- 没有患癌症,但系统预测出患癌症的人为12人(FP)。
- 患有癌症,但系统预测出没有患癌症的人为2人(FN)。
- 患有癌症,系统也预测出患有癌症的人为8人(TP)。
精准率(Presicion)
分类问题的精准率是建立在混淆矩阵的基础上的,那么精准率的公式为:
$$precision = \frac {TP} {TP + FP}$$
还是以预测10000人是否患癌症的例子来说明:
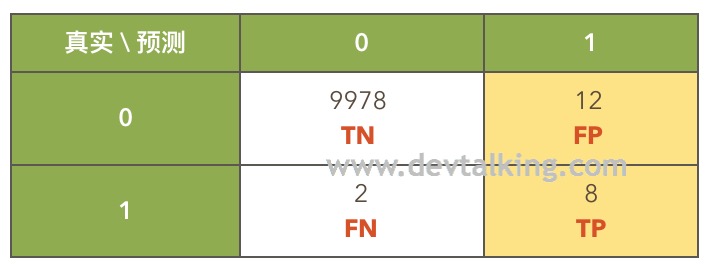
这个例子中,预测患癌的精准率是8 / (8+12) = 40%,既真实患癌并预测出患癌的人数在所有预测出患癌人数中的占比。
召回率(Recall)
分类问题的召回率同样也是建立在混淆矩阵的基础上的,召回率的公式为:
$$recall = \frac {TP} {TP + FN}$$
以预测10000人是否患癌症的例子来说明:
这个例子中,预测患癌的召回率是8 / (8+2) = 80%,既真实患癌并预测出患癌的人数在真实患癌总人数中的占比。
我们之前解释过分类准确度存在的缺陷,那么在这个例子中,我们通过混淆矩阵来直观的看一下这个缺陷。我们的前提是10000个人中患癌的人占比为0.1%,那么健康的人占比为99%,在这种情况下,有极大的可能出现分类准确度为99.9%,但是实际上一个患癌的人都没有预测出来。
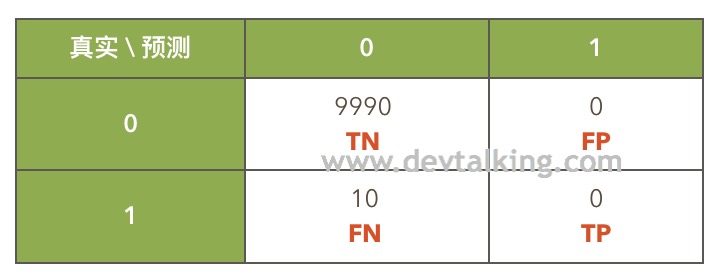
上面这个混淆矩阵就满足我们假定的这个情况,现在来看看分类准确度、精准率和召回率分别是多少:
- 分类准确度:9990 / 10000 = 99.9%
- 精准率:0 / (0+0),无意义,既为0
- 召回率:0 / (10 +0) = 0
现在可以很清晰的看出分类准确度存在的缺陷和混淆矩阵对分类评价的重要性了。
实现精准率和召回率
有了上面的定义,下面我们来实现一下混淆矩阵、精准率和召回率。首先我们使用手写数据作为样本数据,因为手写数据是多分类问题,所以还要对其做一下处理,转换为二分类问题,同时让其数据产生极度偏差:
import numpy as np |
样本数据构建好后,我们先使用逻辑回归训练出模型,先看看分类准确度指标:
from sklearn.model_selection import train_test_split |
下面我们来逐个实现混淆矩阵中的TN、FP、FN、TP:
# 使用逻辑回归模型计算测试特征数据的预测目标值 |
我们通过上面的混淆矩阵来分析一下:
y被拆分后的测试数据量y_test为450,混淆矩阵中的四个熟总和为450。- 真值为0,但预测值为1有2个。
- 真值为1,但预测值为0有9个。
- 真值为1,预测值也为1有36个。
也就是全部预测对的有439个,分类准确度为439 / 450 = 97.56%。下面来看看如何实现精准率和召回率:
# 精准率 |
以上是我们根据定义自己实现的混淆矩阵和精准率、召回率。下面来看看Scikit Learn中封装的它们:
# Scikit Learn 中的混淆矩阵 |
F1 Score
上一节介绍了精准率和召回率,那么如果在一个指标好,一个指标不好的情况下,如何确定一个模型的好坏呢?这就要分情况而视了。像预测股市的系统中,一般主要关注精准率,也就是关注在预测出要涨的股票中的准确程度。那么像医疗相关的系统中就会主要关注召回率,也就是关注在真正患病的人群中预测出的准确程度。如果两个指标都要关注的话,就要引入第三个指标了,那就是F1 Score。
F1 Score定义
我们看多个数的综合情况时,一般情况都会求这些数的平均值,称为算数平均值。但是在机器学习中,算数平均值是有缺陷的,因为它们是求和然后取平均,如果大多数数很大,个别几个数很小的话,平均值并不会被拉下来,但作为机器学习模型的评测标准,可能只要有一个指标不好,那么整个模型就不是一个好的模型。所以我们得使用调和平均值:
$$\frac 1 {F1} = \frac 1 2 (\frac 1 {precision} + \frac 1 {recall})$$
最后换算下来的最终F1 Score公式为:
$$F1 = \frac {2 \cdot precision \cdot recall} {precision + recall}$$
调和平均值的最大特点就是,精准率和召回率只要有一个比较小的话,整个F1 Score也会被拉下来,既避免了算数平均值在评估机器学习算法分类模型时的缺陷。
实现F1 Score
我们知道了F1 Score的定义后,实现它就很容易了:
import numpy as np |
从结果可以看到,当两个指标相等时,F1的值也和它们相等。当其中一个指标比较小时,F1的值也会被拉的比较小。
Scikit Learn 中的 F1 Score
Scikit Learn中也封装了F1 Score,但是它封装时传的参数和我们实现的不太一样,它只需要传入真值和预测值既可,精准率和召回率是在函数中计算的:
from sklearn.metrics import f1_score |
从结果可以看到上一小节中的手写数据的例子,虽然分类准确度达到了97.56%,但是F1 Score只有86.75%,而这个86.75%才是更能真正反应模型好坏程度的指标。
精准率和召回率直接的平衡
在上一篇笔记中,我们了解了逻辑回归的决策边界,比如在二分类问题中,决策边界公式为:
$$\theta^T \cdot X_b = 0$$
当$\theta^T \cdot X_b$大于0时,我们认为分类是1,当小于0时,我们认为分类为0。
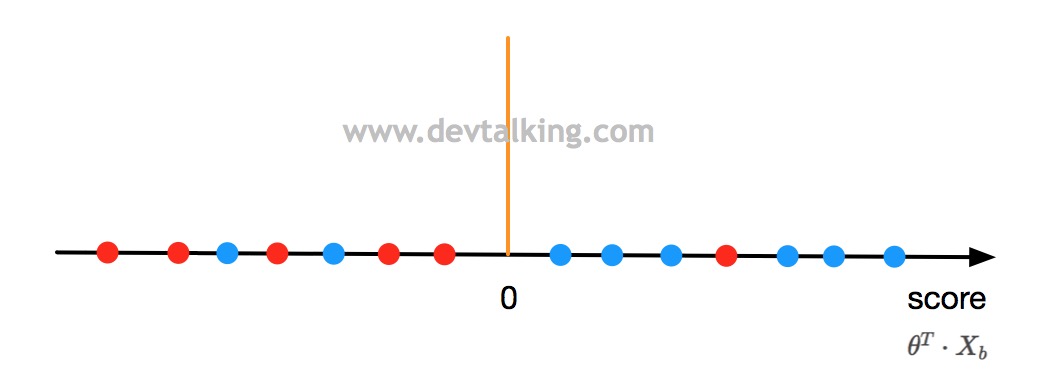
如上图所示,黑色直线表示$\theta^T \cdot X_b$,橘黄色直线所在位置表示区分类别为1还是0的分界点,既大于0是蓝色点类型,小于0是红色点类型。那如果我们让$\theta^T \cdot X_b$不等于0,而等于一个阀值$threshold$呢?
$$\theta^T \cdot X_b = threshold$$
那上面的图就会是下面这样:
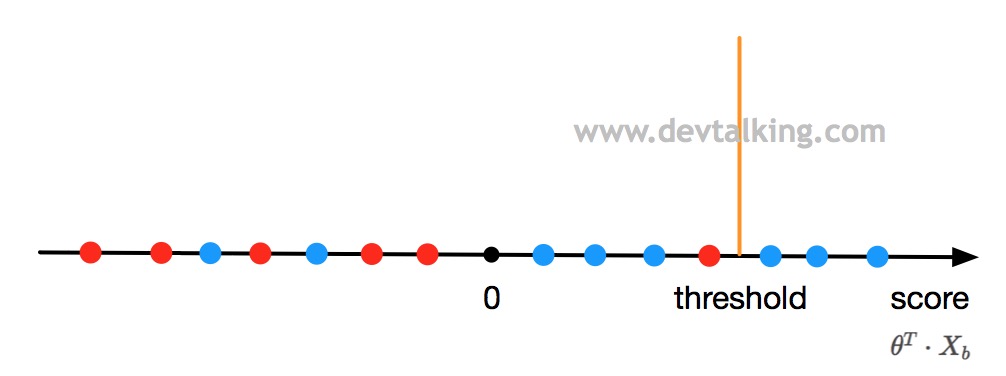
从上面的图看,$threshold$是大于0的,这样就相当于调整了区别分类的分界点位置。那么会影响到什么呢?
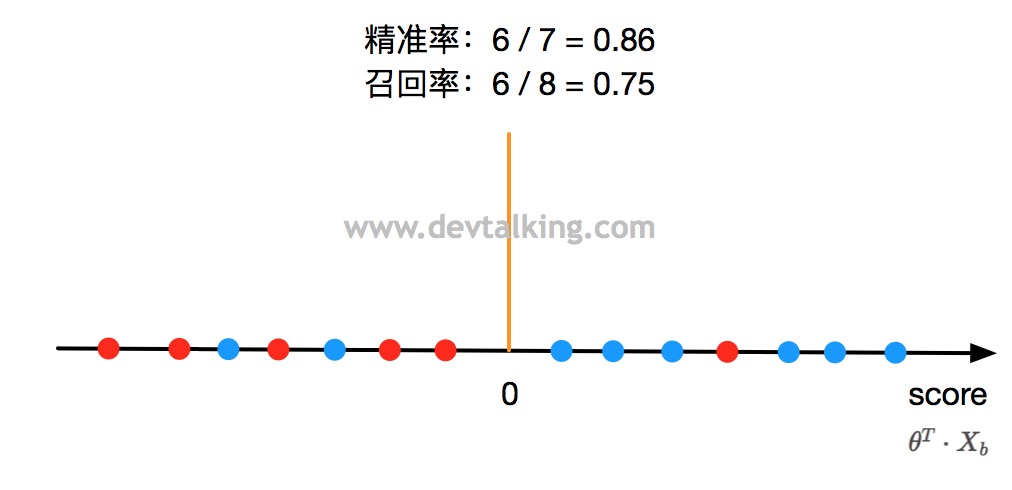
从上图可以看到,当$threshold$为0时,示例中的精准率是0.86,召回率是0.75。
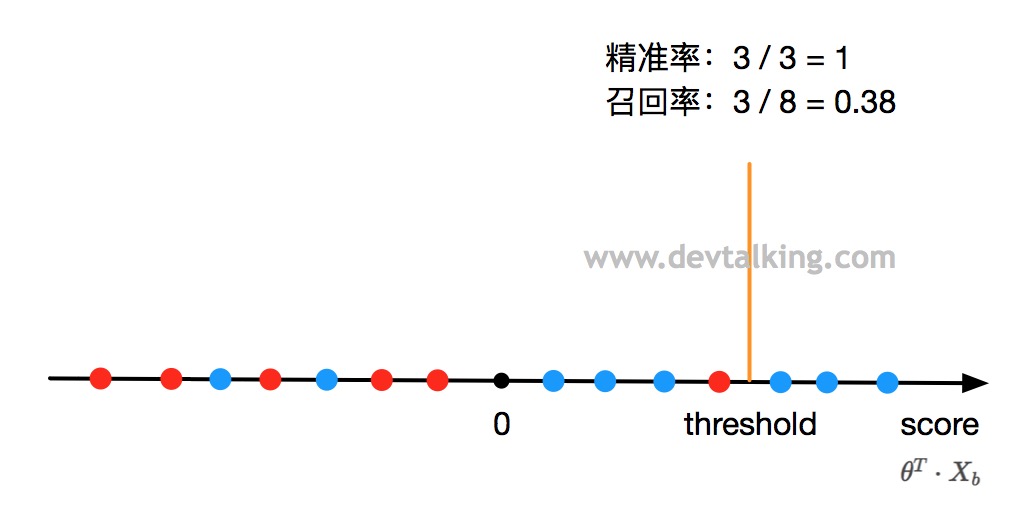
当调整$threshold$大于0后,示例中的精准率是1,召回率是0.38。
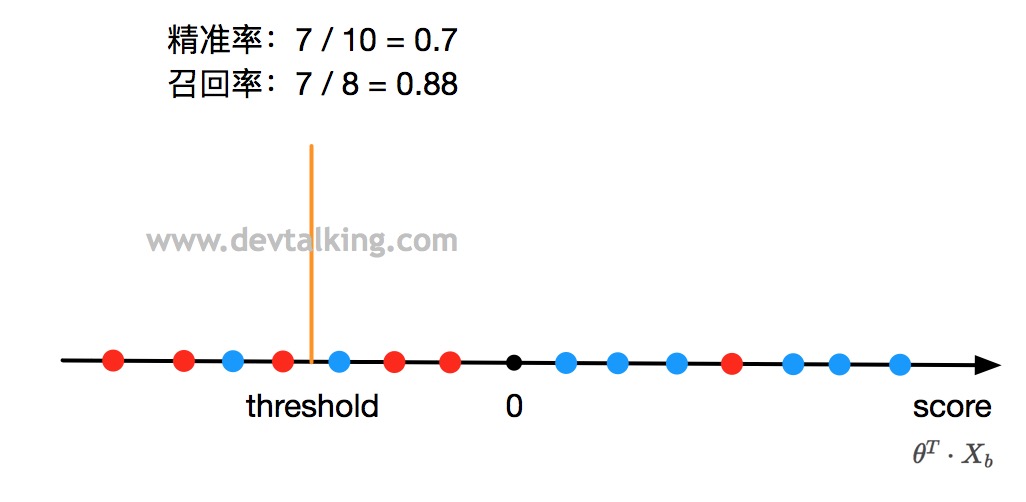
当调整$threshold$小于0后,示例中的精准率是0.7,召回率是0.88。
从这三种情况可以看出,精准率和召回率是互相牵制的,精准率高了,召回率就低。召回率高,精准率就低。所以$threshold$就又是一个超参数,用来调节使精准率和召回率达到平衡。
通过程序验证精准率和召回率的平衡关系
我们还是使用手写数据的样本数据来验证:
import numpy as np |
我们如何设置$threshold$呢,其实Scikit Learn中的逻辑回归提供了一个获取评判分数的函数,也就是上图中黑色直线的Score值:
decision_score = log_reg.decision_function(X_test) |
Scikit Learn中的confusion_matrix、precision_score、recall_score函数都是基于$threshold$为0计算的,也就是判断decision_score中的所有值,如果大于0就分类为1,如果小于0就分类为0。那我们现在将$threshold$调大一点,比如将5作为区分1和0的分界点,那么我们的预测值就可以这样求:
y_predict2 = np.array(decision_score >= 5, dtype='int') |
然后我们再来看看精准率和召回率:
precision_score(y_test, y_predict2) |
再将$threshold$调小看看:
y_predict3 = np.array(decision_score >= -5, dtype='int') |
通过代码我们可以很明显的看到调节$threshold$后,精准率和召回率的变化。
PR曲线
通过上一小节我们知道精准率和召回率是相互牵制的,我也认识了一个新的超参数$threshold$,通过它能调节精准率和召回率。那么我们如何找到一个平衡点,使得精准率和召回率都在一个比较好的水平,换句话说也就是如何找到好的超参数$threshold$。
这一小节就介绍一个工具,帮助我们更好的找到这个超参数,这就是PR曲线(Precision-Recall曲线)。我们直接来看看Scikit Learn中提供的函数:
from sklearn.metrics import precision_recall_curve |
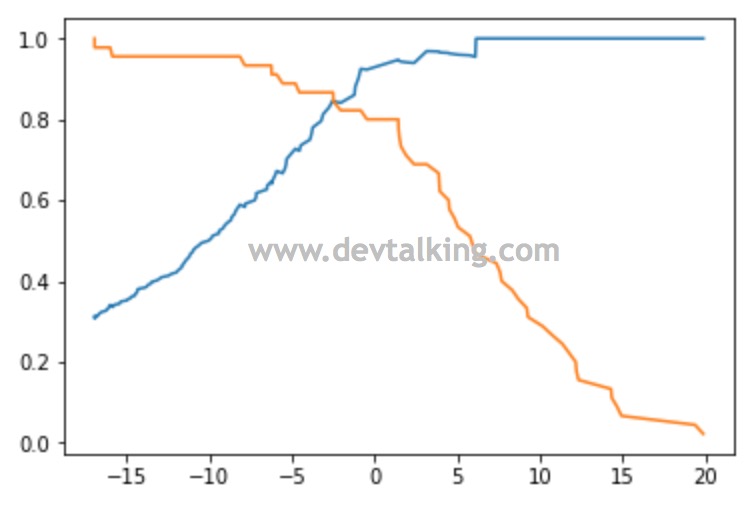
上图的横轴是$threshold$值,蓝色曲线是精准率,黄色曲线是召回率,他们相交点的$threshold$值,就是PR达到平衡的点。
plt.plot(precisions, recalls) |
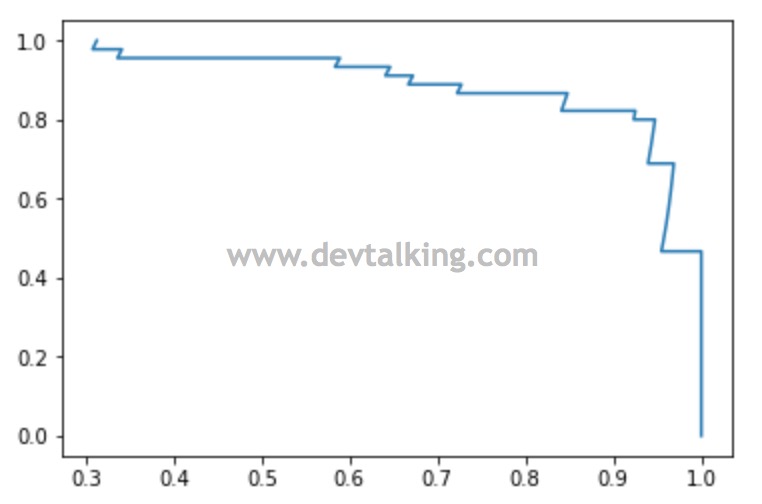
上图中,横轴是精准率,纵轴是召回率。这个图反应了PR的总体趋势。通过这个PR曲线我们除了可以判断选择最优的$threshold$值,还可以判断不同模型的好坏程度。
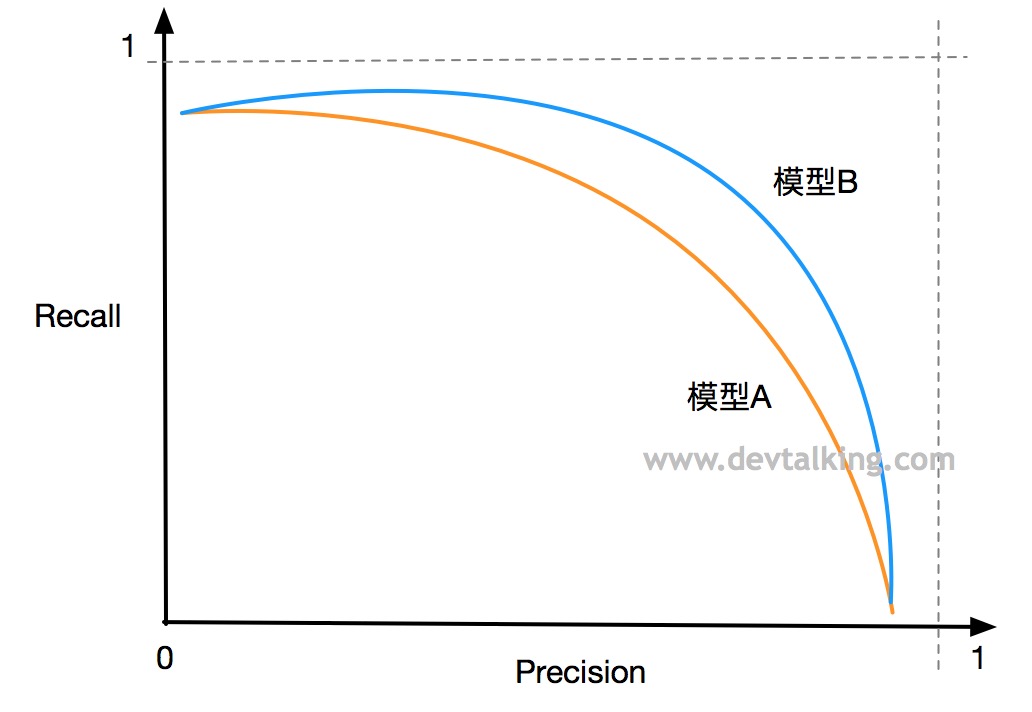
比如上图中的模型A和模型B可以是通过不同的算法训练的出的模型,也可以是同一个算法,通过不同超参数组合训练出的模型。显然模型B要比模型A好,因为模型B无论是精准率还是召回率都要比模型A的高。
ROC曲线
这一小节我们来看一个新的指标,ROC曲线,既接收者操作特征曲线,是Receiver Operation Characteristic Curve缩写,最早出现在信号检测理论中,后来被广泛应用在不同领域。在机器学习中,ROC用来描述分类模型的TPR和FPR之间的关心,从而确定分类模型的好坏。
FPR和TPR
FPR和TPR同样是基于混淆矩阵而来的,FPR的公式为:
$$FPR=\frac {FP} {TN + FP}$$
TPR的公式为:
$$TPR = \frac {TP} {TP + FN}$$
可以看到TPR其实就是Recall指标,而FPR是和TPR相反的指标。下面我们使用Scikit Learn中封装的方法来看看手写数据的TPR、FPR和ROC曲线:
from sklearn.metrics import roc_curve |
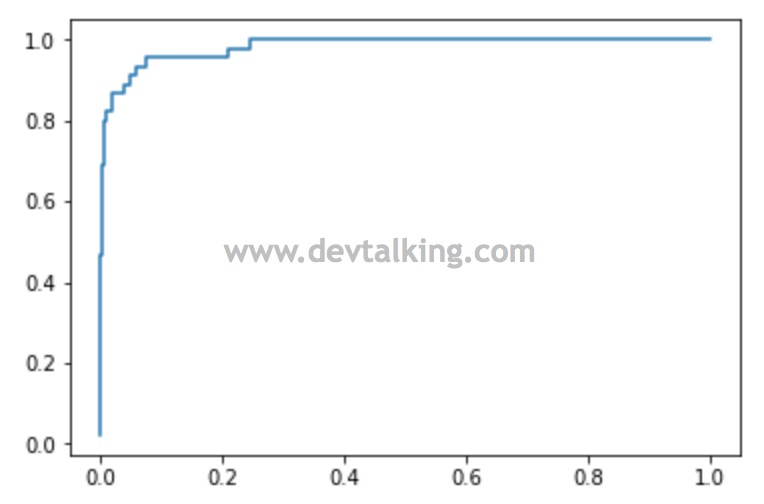
从ROC曲线图可以看出,随着FPR的增大,TPR也是随之增大的。我们通过观察这根曲线下的面积大小来判断分类模型的好坏程度,面积越大,说明分类模型越好。Scikit Learn中也提供了计算这个面积的函数:
from sklearn.metrics import roc_auc_score |
ROC曲线和PR曲线有一个不同之处是,ROC曲线对极度有偏的数据是不敏感的。所以如果样本数据有极度有偏的情况时,通常还是主要使用PR曲线来判断模型的好坏,ROC曲线辅助判断。
多分类问题中的混淆矩阵
我们之前讲的混淆矩阵和精准、召回率都是在二分类问题的前提下。这篇笔记的最后来看看多分类问题中的混淆矩阵。我们同样使用手写数字数据,但这次不再对数据做极度有偏处理了:
import numpy as np |
Scikit Learn 的precision_score方法有一个average参数,默认值为binary,既默认计算二分类问题。如果要计算多分类问题,需要将average参数设置为micro:
from sklearn.metrics import precision_score |
下面来看看这个手写数字十分类问题的混淆矩阵:
from sklearn.metrics import confusion_matrix |
看多分类问题的混淆矩阵和二分类问题的混淆矩阵方法一样,同样行表示真值,列表示预测值。从上面的结果可看到,混淆矩阵的对角线数值最大,这个对角线就是真值和预测值相同的TP值。我们将这个多分类混淆矩阵通过Matplotlib的matshow方法绘制出来,直观的看一下:
cfm = confusion_matrix(y_test, y_predict) |

上面这个图可以很清晰的看到TP值,但是我们希望能从图上直观的分析问题,既这个模型预测错误的数据。下面我们将混淆矩阵做一下转换,求出错误矩阵,既FP值矩阵:
# 首先求出一个向量,这个向量的每个元素表示每个手写数字有多少个样本,也就是将混淆矩阵在列方向,将每行的数加起来。 |

上图中,颜色约亮的格子表示预测错误的数量越多,比如左上角那个白色的格子就表示真值为3,但是有不少样本数据被预测成了8。左下角的白色格子表示真值为8,但是有不少样本数据被预测成了1。所以从这个错误矩阵上可以很好的分析出具体的预测错误点,从而根据这些信息调整分类模型或者样本数据。
申明:本文为慕课网liuyubobobo老师《Python3入门机器学习 经典算法与应用》课程的学习笔记,未经允许不得转载。