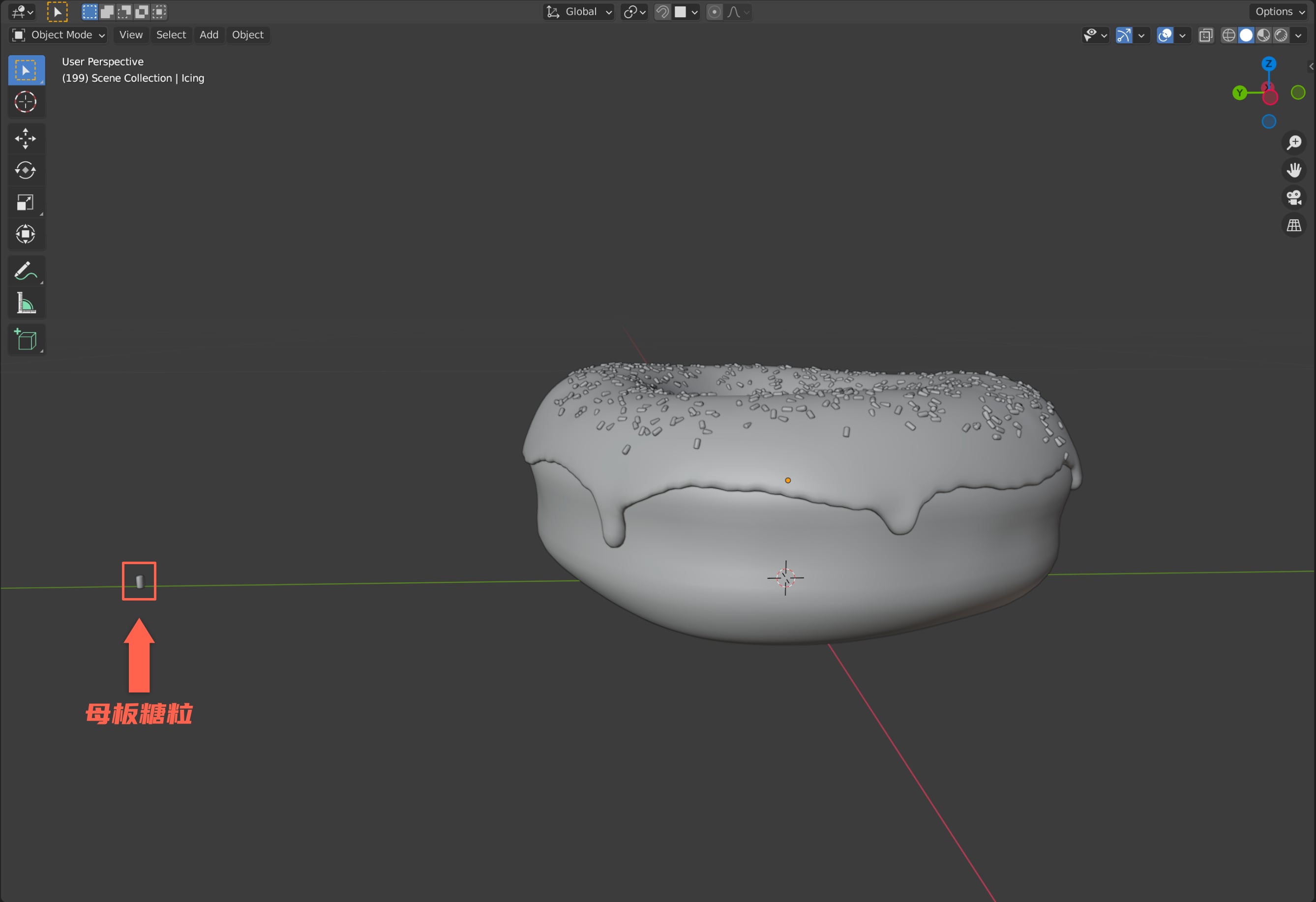
这一节继续优化甜甜圈主体部分,从下面这张真实的照片可以看出,甜甜圈主体表面是坑坑洼洼的(任何面点食物应该都不会很光滑),而目前我们的甜甜圈主体太过光滑,所以显得有点假。

给甜甜圈增加质感
首先点击Edit菜单,选择Preferences,打开Blender设置菜单,然后选择Add-ons,在右侧搜索框搜索node,然后将Node: Node Wrangle插件打上勾。这个插件可以优化和加速节点效果的处理流程。
这一节继续对糖衣进行完善,先来看一张实图:
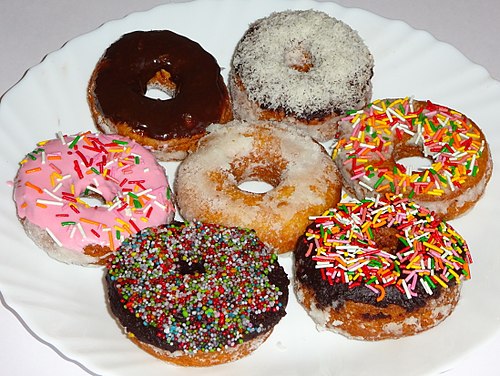
可以看到糖衣上有五颜六色的糖粒(我猜应该是糖),呈小圆柱体,不规则的铺在糖衣上面。这一节就来实现糖衣上的小糖粒。
首先我们先通过集合的方式,对目前场景里的对象做一下分类和整理。选中一个或若干个对象,按下M,然后选择New Collection,就可以将对象放在一个集合中,在《用Blender做甜甜圈学习笔记五 - 雕刻糖衣白模》中使用过。
为甜甜圈和糖衣创建Donut集合,将充当桌面的平面放在Environment集合中,将摄像机和灯光放在Cam & Light集合中。