先来看一张真实的甜甜圈。

一共有三个特点:
- 甜甜圈腰部有一圈凹陷。
- 流下来的糖衣是上小下大的形状,这个和密度大的液体从上往下流的道理是一样的。
- 糖衣的边缘不是光滑的,是坑坑洼洼的。
这一节就是使用Blender的雕刻功能,将甜甜圈和糖衣的这几个特点刻画出来。
应用修改器
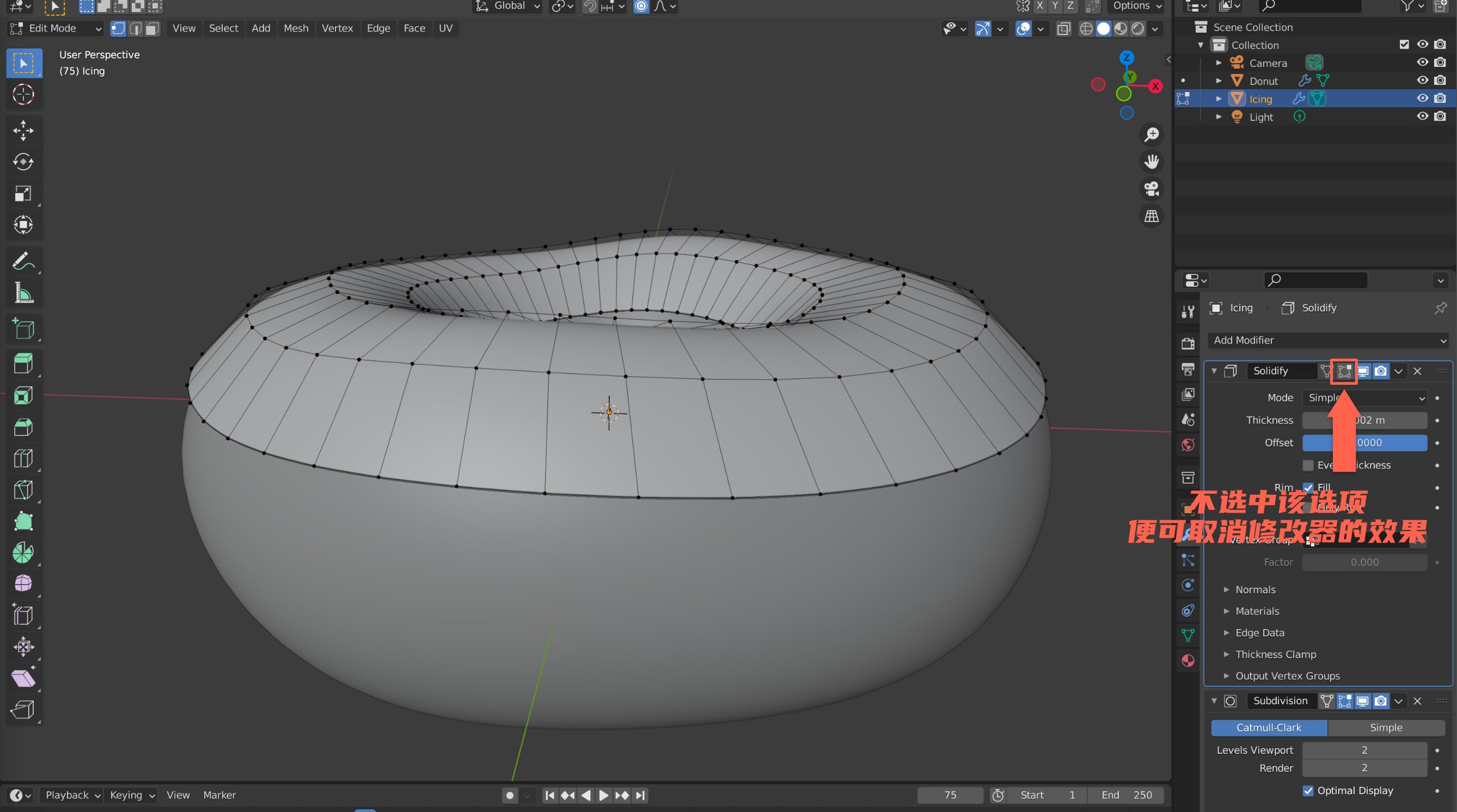
在开始之前,先回忆一下前面我们给甜甜圈和糖衣添加过修改器,但是我们并没有让修改器真正的生效,那么在雕刻前,需要将修改器的内容应用生效。在应用生效修改器之前,我们先对现在的白模复制一份,做个备份,因为修改器一旦生效后,整个拓扑都会发生变化。
选中甜甜圈和糖衣的白模,Shift + D复制一份,然后按下M键,新建一个集合,然后设置为不可见,相当于将复制出来的甜甜圈和糖衣做个备份。