众所周知,游戏行业在当今的互联网行业中算是一棵常青树。在疫情之前的2019年,中国游戏市场营收规模约2884.8亿元,同比增长17.1%。2020年因为疫情,游戏行业更是突飞猛进。玩游戏本就是中国网民最普遍的娱乐方式之一,疫情期间更甚。据不完全统计,截止2019年,中国移动游戏用户规模约6.6亿人,占中国总网民规模8.47亿的77.92%,足以说明,游戏作为一种低门槛、低成本的娱乐手段,已成为大部分人生活中习以为常的一部分。
对于玩家而言,市面上的游戏数量多如牛毛,那么玩家如何能发现和认知到一款游戏,并且持续的玩下去恐怕是所有游戏厂商需要思考的问题。加之2018年游戏版号停发事件,游戏厂商更加珍惜每一个已获得版号的游戏产品,所以这也使得“深度打磨产品质量”和“提高运营精细程度”这两个游戏产业发展方向成为广大游戏厂商的发展思路,无论是新游戏还是老游戏都在努力落实这两点:
- 新游戏:以更充足的推广资源和更完整的游戏内容面向玩家。
- 老游戏:通过用户行为分析,投入更多的精力和成本,制作更优质的版本内容。
这里我们重点来看新游戏。一家游戏企业辛辛苦苦研发三年,等着新游戏发售时一飞冲天。那么问题来了,新游戏如何被广大玩家看到?先来看看游戏行业公司的分类:

- 游戏研发商:研发游戏的公司,生产和制作游戏内容。比如王者荣耀的所有英雄设计、游戏战斗场景、战斗逻辑等等,这些全部由游戏研发公司提供。
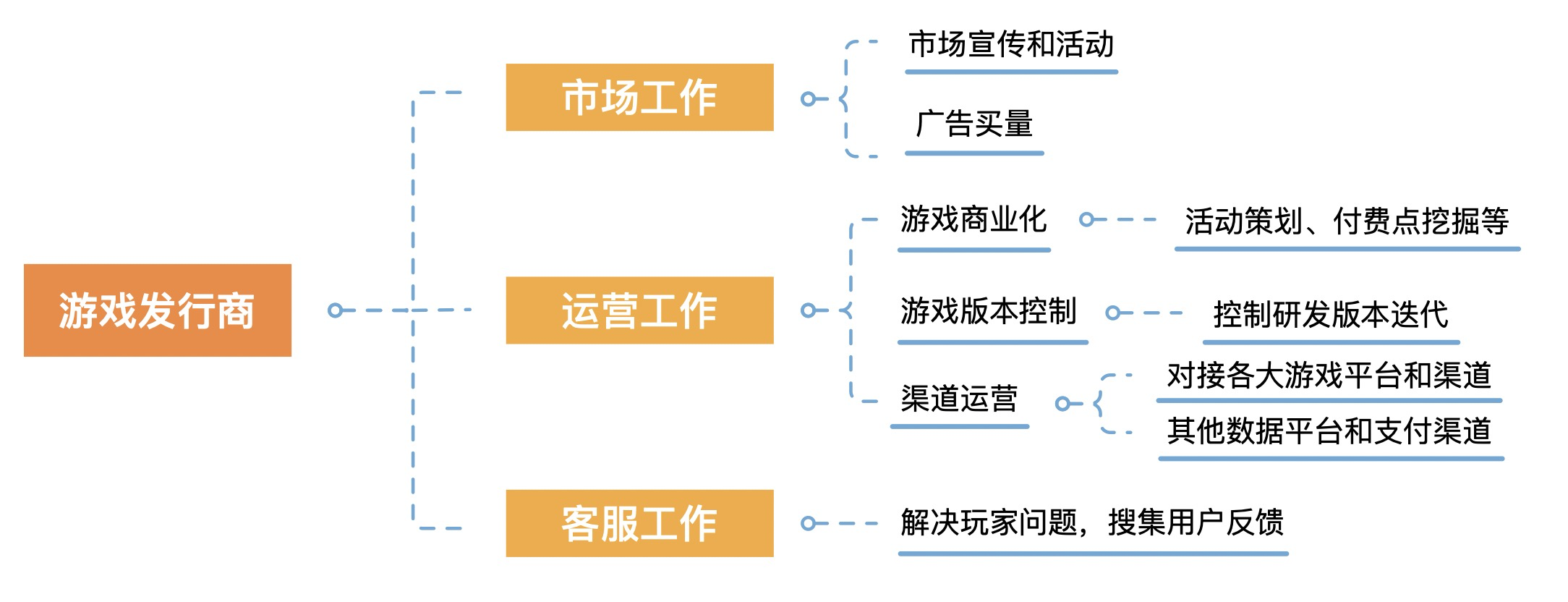
游戏发行商:游戏发行商的主要工作分三大块:市场工作、运营工作、客服工作。游戏发行商把控游戏命脉,市场工作核心是导入玩家,运营工作核心是将用户价值最大化、赚取更多利益。
游戏平台/渠道商:游戏平台和渠道商的核心目的就是曝光游戏,让尽量多的人能发现你的游戏。