这篇笔记主要介绍梯度下降法,梯度下降不是机器学习专属的算法,它是一种基于搜索的最优化方法,也就是通过不断的搜索然后找到损失函数的最小值。像上篇笔记中使用正规方程解实现多元线性回归,基于$X_b\theta$这个模型我们可以推导出$\theta$的数学解,但是很多模型是推导不出数学解的,所以就需要梯度下降法来搜索出最优解。
梯度下降法概念
我们来看看在二维坐标里的一个曲线方程:
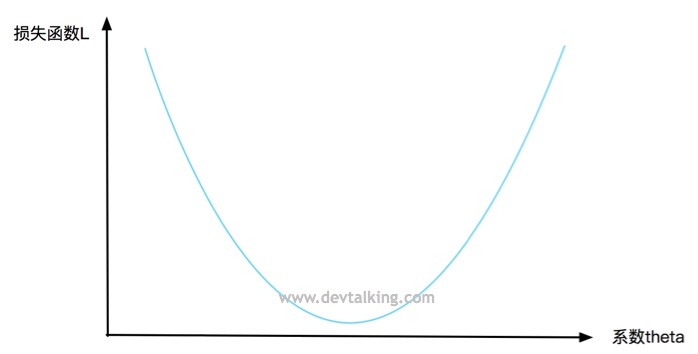
纵坐标表示损失函数L的值,横坐标表示系数$\theta$。每一个$\theta$的值都会对应一个损失函数L的值,我们希望损失函数收敛,既找到一个$\theta$的值,使损失函数L的值最小。
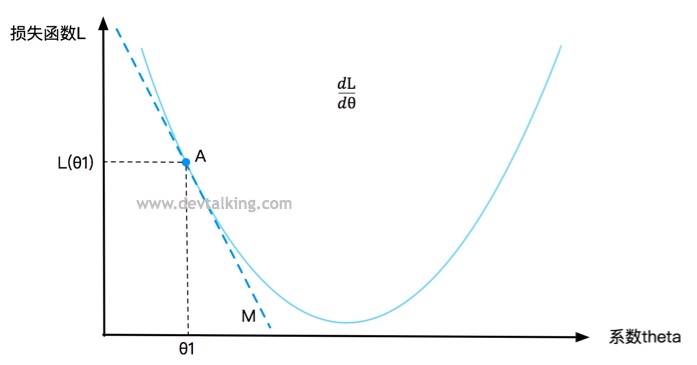
在曲线上定义一点A,对应一个$\theta$值,一个损失函数L的值,要判断点A是否是损失函数L的最小值,既求该点的导数,在第一篇笔记中我解释过,点A的导数就是直线M的斜率,直线M是点A的切线,所以导数描述了一个函数在某一点附近的变化率,并且导数大于零时,函数在区间内单调递增,导数小于零时函数在区间内单调递减。所以$\frac {d L}{d \theta}$表示损失函数L增大的变化率,$-\frac {d L}{d \theta}$表示损失函数L减小的变化率。

再在曲线上定义一点B,在点A的下方,B点的$\theta$值就是A点的$\theta$值加上让损失函数L递减的变化率$-\eta \frac {d L}{d \theta}$,$\eta$称为步长,既B点在$-\frac {d L}{d \theta}$变化率的基础下移动了多少距离,在机器学习中$\eta$这个值也称为学习率。
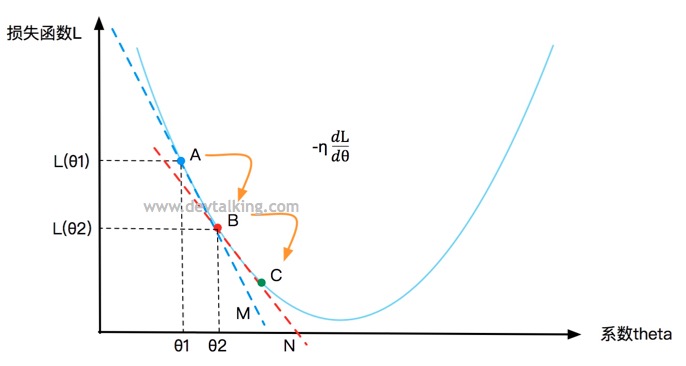
同理还可以再求得点C,然后看是否是损失函数的L的最小值。所以梯度下降法就是基于损失函数在某一点的变化率$-\frac {d L}{d \theta}$,以及寻找下一个点的步长$\eta$,不停的找到下一个点,然后判断该点处的损失函数值是否为最小值的过程。$-\eta \frac {d L}{d \theta}$就称为梯度。
在第一篇笔记中将极值的时候提到过,当曲线或者曲面很复杂时,会有多个驻点,既局部极值,所以如果运行一次梯度下降法寻找损失函数极值的话很有可能找到的只是局部极小值点。所以在实际运用中我们需要多次运行算法,随机化初始点,然后进行比较找到真正的全局极小值点,所以初始点的位置是梯度下降法的一个超参数。
不过在线性回归的场景中,我们的损失函数$\sum_{i=1}^m(y^{(i)}-\hat y^{(i)})^2$是有唯一极小值的,所以暂时不需要多次执行算法搜寻全局极值。
梯度下降的步长
步长在梯度下降法中非常重要,这里着重说一下。
- $\eta$在机器学习中称为学习率(Learning rate)。
- $\eta$的取值影响获得最优解的速度。想象一下如果$\eta$过小,那么寻找的点就会变得很多,收敛速度下降。如果$\eta$过大可能会不断错过最优解,同样影响收敛速度。
- $\eta$取值不合适时甚至得不到最优解。比如$\eta$值过大会造成损失函数值越来越大。
- $\eta$也是梯度下降法的一个超参数。可能会有搜索最佳$\eta$的过程。
实现梯度下降法
我们在Jupyter Notebook中来看看如何实现梯度下降法:
import numpy as np |
下面我们来定义变化率$\frac {d L}{d \theta}$和损失函数:
# 变化率 |
然后来看看实现梯度下降的过程:
# 步长默认设为0.1 |
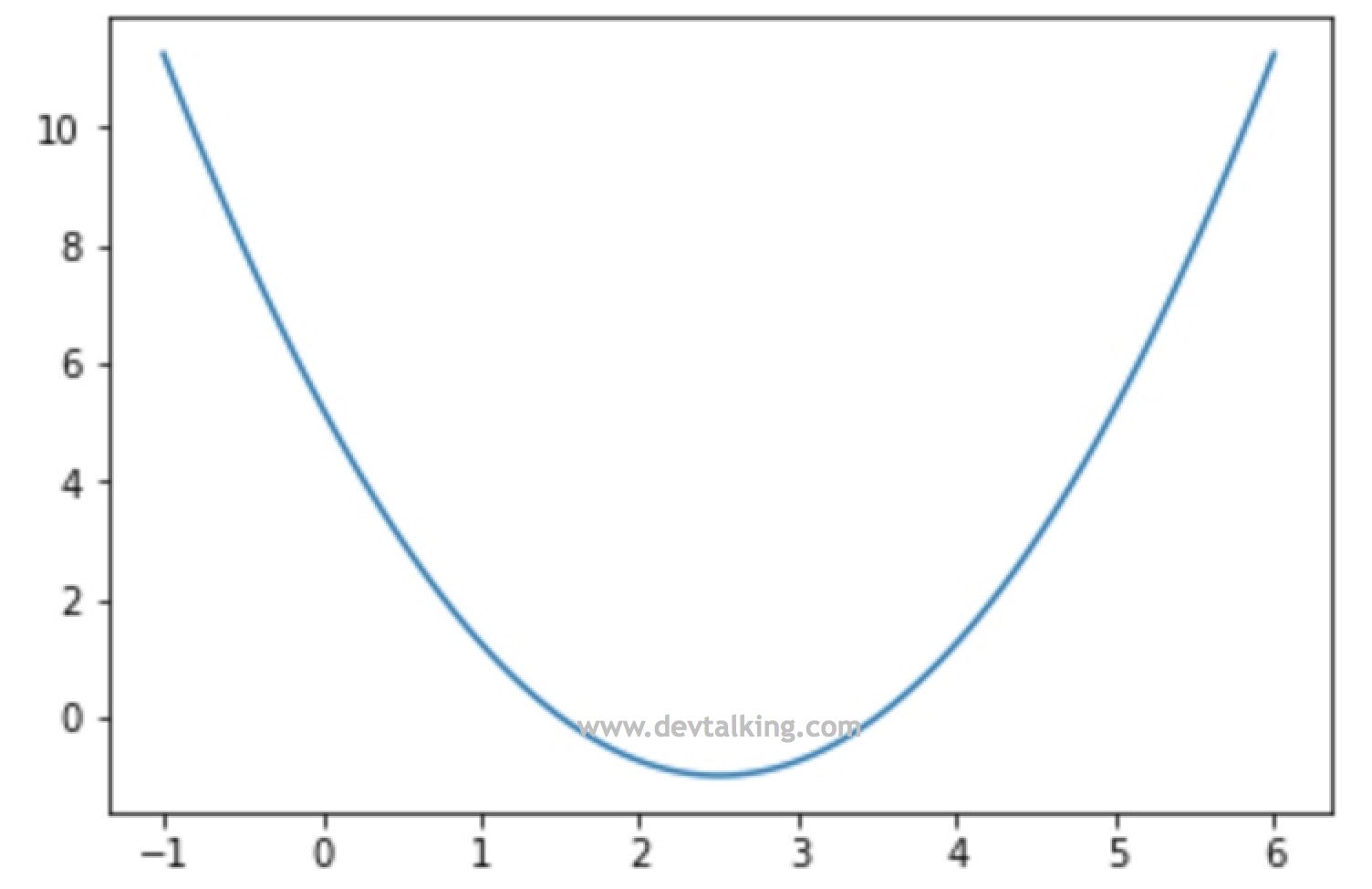
得到的$\theta$值为2.5,损失函数的极小值为-1,代入方程$(\theta - 2.5)^2-1$可验证我们的求解是正确的。
Theta的变化
我们将每次$\theta$的值记下来,然后描绘出来,看看是如何变化的:
eta = 0.1 |

从上面的示例代码中看到,一共经历了45次的查找得到了让函数达到最小值的$\theta$。并且看到一开始因为曲线比较陡,所以梯度比较大,两个点之间的间隔比较大,到曲线底部的时候因为曲线开始平缓,梯度逐渐变小,每个点之间的间隔就越来越小。
我们将步长调大一些,看看$\theta$的查找轨迹是怎样的:
eta = 0.8 |
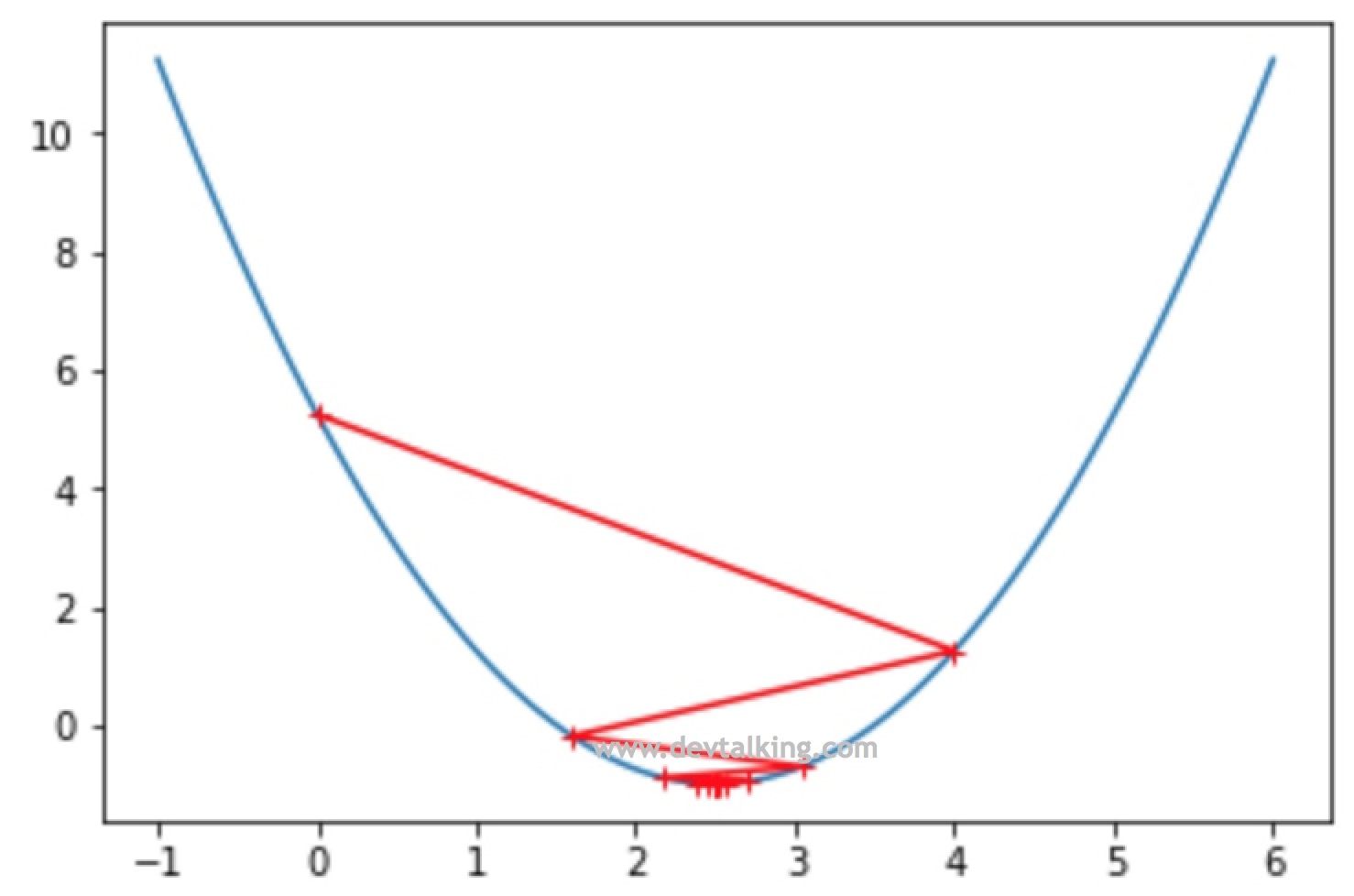
从图中可以看到,第一次查找的时候就越过了极值点,找到了曲线另一侧的点,不过好在损失函数的值还是递减的状态所以最终还是找到了极值点。
我们将步长再调大点,看会发生什么情况:
def L(theta): |

从图中看到每次找到的$\theta$会使损失函数越来越大,根本无法找到极小值。所以步长的确定非常重要,不过一般情况下,我们将步长设为0.01是比较保险的做法,但是如果想使算法在各方面达到最优,那么还是需要先对步长这个超参数进行严谨的确定。
求导概念复习
在看如何使用梯度下降解决线性回归问题前,我们先来复习一下求导的知识。
代数函数的求导
- $\frac {dM}{dx}=0$
- $\frac {dx^n}{dx}=nx^{n-1}$
- $\frac {d|x|}{dx}=\frac {x}{|x|}$
一般求导定则
线性定则
$$ \frac {d(Mf)}{dx}=M\frac {df}{dx} $$
$$ \frac {d(f\pm g)}{dx}=\frac {df}{dx} \pm \frac {dg}{dx} $$
乘法定则
$$\frac {dfg}{dx}=\frac {df}{dx}g + f\frac {dg}{dx}$$
除法定则
$$ \frac {d \frac f g} {dx} = \frac {\frac {df} {dx} g - f \frac {dg} {dx}} {g^2} \ \ \ (g\neq 0) $$
倒数定则
$$ \frac {d \frac 1 g} {dx} = \frac {-\frac {dg} {dx}} {g^2} \ \ \ (g\neq 0) $$
复合函数求导法则
$$ \frac {df[g(x)]} {dx} = \frac {df(g)} {dg} \frac {dg} {dx} = f’[g(x)]g’(x) $$
线性回归中使用梯度下降法
上一节通过一维场景解释了梯度下降法,这一节在高维的场景中看看如何使用梯度下降法解决线性回归的问题。

在线性回归的问题中注意一下三个方面:
- 首先损失函数$\sum_{i=1}^m(y^{(i)}-\hat y^{(i)})^2$是明确的,前面用正规方程解实现的时候已经推导过。
- 其次系数$\theta$不是一维的了,而是多维的,既$\theta$是一个向量。
- 最后损失函数不是对一维系数$\theta$求全导,而是对$\theta$向量求偏导,也就是对向量里的每一个$\theta$求导数,记为$\nabla L$,既梯度。
在上一篇笔记中我们推导过$\hat y^{(i)}$的函数:
$$ \hat y^{(i)} = \theta _0+\theta_1X_1^{(i)}+\theta_2X_2^{(i)}+…+\theta_nX_n^{(i)} $$
所以代入损失函数后就得:
$$\sum_{i=1}^m (y^{(i)}-\theta_0-\theta_1X_1^{(i)}-\theta_2X_2^{(i)}-…-\theta_nX_n^{(i)})^2$$
在讲正规方程解时我们推导过,上面的函数可以转换为:
$$\sum_{i=1}^m(y^{(i)}-X_b^{(i)} \theta)^2$$
我们的目标就是让上面的函数尽可能的小,根据之前讲过的概念,我们知道损失函数的梯度就是对$\theta$向量中的每个$\theta$求导,并且在上篇笔记中我们知道$\theta$向量是一个列向量,根据复合函数求导定则,所以损失函数L的梯度为:
$$ \nabla L(\theta) = \begin{bmatrix}
\frac {\partial L} {\partial \theta_0} \\
\frac {\partial L} {\partial \theta_1} \\
\frac {\partial L} {\partial \theta_2} \\
… \\
\frac {\partial L}{\partial \theta_n} \\
\end{bmatrix} = \begin{bmatrix}
\sum_{i=1}^m 2(y^{(i)}-X_b^{(i)}\theta)(-1) \\
\sum_{i=1}^m 2(y^{(i)}-X_b^{(i)}\theta)(-X_1^{(i)}) \\
\sum_{i=1}^m 2(y^{(i)}-X_b^{(i)}\theta)(-X_2^{(i)}) \\
… \\
\sum_{i=1}^m 2(y^{(i)}-X_b^{(i)}\theta)(-X_n^{(i)}) \\
\end{bmatrix} $$
将2提到外面,然后将后面的负号移进前面的括号里得:
$$\begin{bmatrix}
\sum_{i=1}^m 2(y^{(i)}-X_b^{(i)}\theta)(-1) \\
\sum_{i=1}^m 2(y^{(i)}-X_b^{(i)}\theta)(-X_1^{(i)}) \\
\sum_{i=1}^m 2(y^{(i)}-X_b^{(i)}\theta)(-X_2^{(i)}) \\
… \\
\sum_{i=1}^m 2(y^{(i)}-X_b^{(i)}\theta)(-X_n^{(i)}) \\
\end{bmatrix}=2\begin{bmatrix}
\sum_{i=1}^m (X_b^{(i)}\theta-y^{(i)}) \\
\sum_{i=1}^m (X_b^{(i)}\theta-y^{(i)})X_1^{(i)} \\
\sum_{i=1}^m (X_b^{(i)}\theta-y^{(i)})X_2^{(i)} \\
… \\
\sum_{i=1}^m (X_b^{(i)}\theta-y^{(i)})X_n^{(i)} \\
\end{bmatrix}$$
可以发现上面公式中每个元素都经过了m求和,这样带来的问题就是梯度受样本数据数量的影响极大,不过在线性回归的评测标准一节中讲到的均方误差MSE就是为了解决这个问题的,所以我们将损失函数直接转变为MSE:
$$\frac 1 {m}\sum_{i=1}^m(y^{(i)}-X_b^{(i)} \theta)^2$$
那么对MSE求梯度的结果自然也是损失函数求梯度后乘以1/m:
$$\frac 2 m\begin{bmatrix}
\sum_{i=1}^m (X_b^{(i)}\theta-y^{(i)}) \\
\sum_{i=1}^m (X_b^{(i)}\theta-y^{(i)})X_1^{(i)} \\
\sum_{i=1}^m (X_b^{(i)}\theta-y^{(i)})X_2^{(i)} \\
… \\
\sum_{i=1}^m (X_b^{(i)}\theta-y^{(i)})X_n^{(i)} \\
\end{bmatrix}$$
实现线性回归中的梯度下降法
我们先在Jupyter Notebook中来实现,然后再在PyCharm中进行封装:
import numpy as np |
# 定义损失函数 |
可以看到我们得到的结果,解决为4,斜率为3,和我们拟定的线性方程是一致的。
下面我们在PyCharm中封装梯度下降法。在LinearRegression类中再增加一个fit_gd方法,和fit_normal方法区分开,表明是用梯度下降法进行训练:
# 使用梯度下降法,根据训练数据集X_train,y_train训练LinearRegression模型 |
优化梯度公式
我们先将之前推导出来的梯度公式写出来:
$$\nabla L = \frac 2 m\begin{bmatrix}
\sum_{i=1}^m (X_b^{(i)}\theta-y^{(i)}) \\
\sum_{i=1}^m (X_b^{(i)}\theta-y^{(i)})X_1^{(i)} \\
\sum_{i=1}^m (X_b^{(i)}\theta-y^{(i)})X_2^{(i)} \\
… \\
\sum_{i=1}^m (X_b^{(i)}\theta-y^{(i)})X_n^{(i)} \\
\end{bmatrix}$$
将展开来看:
$$\nabla L = \frac 2 m\begin{bmatrix}
(X_b^{(1)}\theta-y^{(1)})+(X_b^{(2)}\theta-y^{(2)})+…+(X_b^{(m)}\theta-y^{(m)}) \\
(X_b^{(1)}\theta-y^{(1)})X_1^{(1)}+(X_b^{(2)}\theta-y^{(2)})X_1^{(2)}+…+(X_b^{(m)}\theta-y^{(m)})X_1^{(m)} \\
(X_b^{(1)}\theta-y^{(1)})X_2^{(1)}+(X_b^{(2)}\theta-y^{(2)})X_2^{(2)}+…+(X_b^{(m)}\theta-y^{(m)})X_2^{(m)} \\
… \\
(X_b^{(1)}\theta-y^{(1)})X_n^{(1)}+(X_b^{(2)}\theta-y^{(2)})X_n^{(2)}+…+(X_b^{(m)}\theta-y^{(m)})X_n^{(m)} \\
\end{bmatrix}$$
将第一行的元素形式统一,每项都乘以$X_0$,并且$X_0$恒等于1:
$$\nabla L = \frac 2 m\begin{bmatrix}
(X_b^{(1)}\theta-y^{(1)})X_0^{(1)}+(X_b^{(2)}\theta-y^{(2)})X_0^{(2)}+…+(X_b^{(m)}\theta-y^{(m)})X_0^{(m)} \\
(X_b^{(1)}\theta-y^{(1)})X_1^{(1)}+(X_b^{(2)}\theta-y^{(2)})X_1^{(2)}+…+(X_b^{(m)}\theta-y^{(m)})X_1^{(m)} \\
(X_b^{(1)}\theta-y^{(1)})X_2^{(1)}+(X_b^{(2)}\theta-y^{(2)})X_2^{(2)}+…+(X_b^{(m)}\theta-y^{(m)})X_2^{(m)} \\
… \\
(X_b^{(1)}\theta-y^{(1)})X_n^{(1)}+(X_b^{(2)}\theta-y^{(2)})X_n^{(2)}+…+(X_b^{(m)}\theta-y^{(m)})X_n^{(m)} \\
\end{bmatrix}$$
下面我们来两个矩阵,A为一个1行m列的矩阵,B为一个m行n列的矩阵:
$$A=\frac 2 m \begin{bmatrix}X_b^{(1)}\theta-y^{(1)}& X_b^{(2)}\theta-y^{(2)}& … &X_b^{(m)}\theta-y^{(m)}\end{bmatrix}$$
$$B=\begin{bmatrix}
X_0^{(1)}& X_1^{(1)}& X_2^{(1)}& … & X_n^{(1)} \\
X_0^{(2)}& X_1^{(2)}& X_2^{(2)}& … & X_n^{(2)} \\
… \\
X_0^{(m)}& X_1^{(m)}& X_2^{(m)}& … & X_n^{(m)}
\end{bmatrix}$$
在第二篇笔记中我们复习过矩阵的运算,让A矩阵点乘B矩阵会得到一个1行n列的新矩阵:
$$A \cdot B=\frac 2 m \begin{bmatrix}X_b^{(1)}\theta-y^{(1)}& X_b^{(2)}\theta-y^{(2)}& … &X_b^{(m)}\theta-y^{(m)}\end{bmatrix} \cdot\ \begin{bmatrix}
X_0^{(1)}& X_1^{(1)}& X_2^{(1)}& … & X_n^{(1)} \\
X_0^{(2)}& X_1^{(2)}& X_2^{(2)}& … & X_n^{(2)} \\
… \\
X_0^{(m)}& X_1^{(m)}& X_2^{(m)}& … & X_n^{(m)}
\end{bmatrix} \\
=\begin{bmatrix}
(X_b^{(1)}\theta-y^{(1)})X_0^{(1)}+(X_b^{(2)}\theta-y^{(2)})X_0^{(2)}+…+(X_b^{(m)}\theta-y^{(m)})X_0^{(m)}& \\ (X_b^{(1)}\theta-y^{(1)})X_1^{(1)}+(X_b^{(2)}\theta-y^{(2)})X_1^{(2)}+…+(X_b^{(m)}\theta-y^{(m)})X_1^{(m)}& \\
…\\
(X_b^{(1)}\theta-y^{(1)})X_n^{(1)}+(X_b^{(2)}\theta-y^{(2)})X_n^{(2)}+…+(X_b^{(m)}\theta-y^{(m)})X_n^{(m)}
\end{bmatrix}$$
注意上面$A \cdot B$的矩阵是1行n列的矩阵,将其转置后就称为了n行1列的矩阵,正是之前展开的梯度$\nabla L$,所以我们的梯度公式可写为:
$$\nabla L = \frac 2 m((X_b \theta - y)^\top X_b)^\top=\frac 2 m X_b^\top(X_b \theta - y)$$
如此一来我们就可以修改一下之前封装的梯度的方法了:
# 定义梯度 |
此时就可以用一行代码取代之前的for循环来实现梯度了。
用真实数据测试梯度下降法
我们用Scikit Learn提供的波士顿房价来测试一下梯度下降法:
import numpy as np |
从前10行的数据中可以看出来,数据之间的差距非常大,不同于正规方程法的$\theta$有数学解,在梯度下降中会非常影响梯度的值,既影响$\theta$的搜索,从而影响收敛速度和是否能收敛,所以一般在使用梯度下降法前,都需要对数据进行归一化处理,将数据转换到同一尺度下。在第三篇笔记中介绍过数据归一化的方法,Scikit Learn中也提供了数据归一化的方法,我们就使用Scikit Learn中提供的方法对波士顿数据进行归一化:
# 先将样本数据拆分为训练样本数据和测试样本数据 |
可以看到数据都在同一个尺度内了,然后我们用优化后的梯度下降法来训练归一化后的样本数据:
from myML.LinearRegression import LinearRegression |
看到结果与我们之前使用正规方程法得到的结果是一致的。
随机梯度下降法
在实际的运用中,训练数据的量级往往都很大,我们目前实现梯度下降法是需要让每一个样本数据都参与梯度计算的,称为批量梯度下降,所以当样本数据量很大的时候,计算梯度的速度就会很慢,所以这一节我们来看看改进这个情况的随机梯度下降法。
以一个山谷的俯视示意图为例,先来看看批量梯度下降法对$\theta$值的查找轨迹:

可以看到呈现出的轨迹是平滑下降的,每一个$\theta$值都比上一个$\theta$值小,最终找到使损失函数达到极小值的$\theta$。这是因为每一个$\theta$都会对所有样本进行了计算,为了增加拟合效率,对每一个$\theta$,我们不对所有样本进行计算,而是每次只取一个样本进行计算,取多次来找到最终的$\theta$值,这就是随机梯度下降的基本思想。
那么我们再来看看随机梯度下降法的$\theta$查找轨迹:

因为每次只随机取一个样本进行计算,所以可以看到随机梯度下降法查找$\theta$的轨迹是也是随机的,很多时候搜索下一个$\theta$的路径并不是最短路径,并且下一个$\theta$的损失函数值比上一个$\theta$的损失函数值还要大,但是最终依然会找到使损失函数达到极小值的$\theta$。
我们来看看梯度公式:
$$\frac 2 m\begin{bmatrix}
\sum_{i=1}^m (X_b^{(i)}\theta-y^{(i)}) \\
\sum_{i=1}^m (X_b^{(i)}\theta-y^{(i)})X_1^{(i)} \\
\sum_{i=1}^m (X_b^{(i)}\theta-y^{(i)})X_2^{(i)} \\
… \\
\sum_{i=1}^m (X_b^{(i)}\theta-y^{(i)})X_n^{(i)} \\
\end{bmatrix}$$
按照随机梯度下降的思路,每次只取一个样本进行计算,也就是i每次只取一个值:
$$2\begin{bmatrix}
(X_b^{(i)}\theta-y^{(i)}) \\
(X_b^{(i)}\theta-y^{(i)})X_1^{(i)} \\
(X_b^{(i)}\theta-y^{(i)})X_2^{(i)} \\
… \\
(X_b^{(i)}\theta-y^{(i)})X_n^{(i)} \\
\end{bmatrix}$$
向量化后可得:
$$2(X_b^{(i)})^\top(X_b^{(i)} \theta - y^{(i)})$$
注意上面这个公式并不是梯度公式,而是搜索$\theta$的某一个方向,批量梯度下降是不放过任何一个搜索$\theta$的方向,而随机梯度下降是每次选择一个方向进行搜索。另外需要注意的是随机梯度下降法中的步长(学习率)并不是固定不变的,不然就无法找补随机路径的不足了,所以随机梯度下降法中的步长是根据搜索次数的增加而降低的,也就是逐渐递减的。那么学习率的公式我们首先想到的就是取搜索次数的倒数:
$$\eta=\frac 1 {i\_iters}$$
但是如果搜索次数很小或者很大的时候都会出现问题,前者会导致学习率下降的幅度过大,而后者会导致学习率下降的幅度过小,所以我们将分母加上一个常数,分子也用一个常数,这样就能保证学习率的递减幅度在一个较为平滑的状态:
$$\eta=\frac a {i\_iters + b}$$
a和b其实就是随机梯度下降法的两个超参数了,不过这里我们不对这两个超参数进行搜索,我们使用最佳实践就好,一般取a为5,b为50。
另外一个关键的超参数是搜索次数,假设取样本数据量的1/3作为搜索次数,因为每次是随机取一个样本数据,那势必会有一部分样本数据取不到,从而不会计算,并且取到的样本数据里也会有重复的数据,这样虽然收敛时间减少了,但是准确率却会打折扣,那么为了训练数据的准确性,我们希望每次搜索到的样本数据不重复,并且能所有的样本数据都希望在某一方向进行计算,所以将搜索次数的概念转变一下,既为随机搜索样本数据,且不重复,且所有样本数据都被搜索到一遍的轮数。这样一来,这个轮数可以很小,一般搜索4轮5轮既可。
实现随机梯度下降法
我们先模拟10万条样本数据,然后用批量梯度下降法训练一次,看看拟合时间:
import numpy as np |
我们看到使用批量梯度下降法计算出的截距和系数和拟定的线性方程中的截距和系数是差不多的,并且拟合时间用了5.19秒。
下面我们直接在PyCharm中封装随机梯度下降的方法,在LinearRegression类中增加fit_sgd方法:
# 使用随机梯度下降法,根据训练数据集X_train,y_train训练LinearRegression模型 |
然后在Jupyter Notebook中使用封装好的随机梯度下降法来训练刚才的数据:
lr1 = LinearRegression() |
可以看到最终的结果和批量梯度下降法训练出的是差不多的,但是拟合时间只用了971毫秒。
Scikit Learn中的随机梯度下降法
这一节我们用真实的波士顿房价数据,使用Scikit Learn中的随机梯度下降进行训练看看:
import numpy as np |
再来看看使用我们自己封装的随机梯度下降训练波士顿房价数据:
from myML.LinearRegression import LinearRegression |
可以看到在同样的搜索轮数,相同的评分值情况下,Scikit Learn中的随机梯度下降法的收敛时间远远小于我们自己实现的随机梯度下降法,这是因为Scikit Learn中实现的时候使用了大量优化的算法,我们只是使用了最核心的思想进行封装,这点需要大家知晓。
关于梯度的调试
从字面意思就不难看出梯度下降法中梯度的重要性,在线性回归问题中,我们尚且能推导出梯度的公式,但在一些复杂的情况下,推导梯度的公式非常不容易,所以我们推导出的梯度公式是否合理,是否是正确的,就需要有一个方法来验证。这一小节就给大家介绍一个梯度调试的方法。

拿一维场景来说,A点的梯度也就是导数是它切线M的斜率。然后我们在直线M的右侧再画出一条平行与直线M的直线N,直线N的斜率与直线M的斜率近乎相等,此时直线N与曲线有两个相交点B和点C,这两个点分别在A点的负方向,也就是下上方,和在A点的正方向,也就是在下方,此时直线M也称为曲线的割线:

在第一篇笔记中讲过直线的斜率定义,既对于两个已知点$(x_1,y_1)$和$(x_2,y_2)$,如果$x_1$不等于$x_2$,则经过这两点直线的斜率为$(y_1-y_2)/(x_1-x_2)$。我们假设点B和点C相距点A为$\epsilon$,所以直线N的斜率为:
$$\frac {L(\theta + \epsilon)-L(\theta - \epsilon)}{\theta + \epsilon - (\theta - \epsilon)}=\frac {L(\theta + \epsilon)-L(\theta - \epsilon)}{2\epsilon}$$
通过这个公式就可以模拟计算出某一点的导数。对于高维的梯度也是同样的道理。
$$\theta = (\theta_0,\theta_1,\theta_2,…,\theta_n)$$
$$\frac {\partial L}{\partial \theta}=(\frac {\partial L}{\partial \theta_0},\frac {\partial L}{\partial \theta_1},\frac {\partial L}{\partial \theta_2},…,\frac {\partial L}{\partial \theta_n})$$
高维情况中,$\theta$和梯度如上所示,如果我们要模拟计算$\theta_0$的梯度,首先得出$\theta_0$上方和下方的$\theta$:
$$\theta_0^+ = (\theta_0+\epsilon,\theta_1,\theta_2,…,\theta_n)$$
$$\theta_0^- = (\theta_0-\epsilon,\theta_1,\theta_2,…,\theta_n)$$
那么模拟出的$\theta_0$导数为:
$$\frac {\partial L}{\partial \theta_0}=\frac {L(\theta_0^+)-L(\theta_0^-)}{2\epsilon}$$
以此类推,可以模拟计算出所有$\theta$的导数,从而模拟计算出梯度。虽然该方法与损失函数形态无关,但是对每个$\theta$导数的模拟计算都需要将两组$\theta$向量代入损失函数进行计算,时间复杂度还是非常高的,但是有一个优势是可以忽略损失函数形态。所以我们一般用这种方式在一开始投入一些时间算出梯度,因为这个梯度是基于斜率的数学定理计算出的,所以它可以认为是一个合理的梯度,然后将它作为标准来验证通过梯度下降法计算出的梯度的正确性。
实现梯度的调试方法
我们在PyCharm中对我们封装好的梯度下降做一下改动,首先在LinearRegression类中增加一个名为dL_debug()的方法:
def dL_debug(theta, X_b, y, epsilon=0.01): |
然后对fit_gd()方法增加一个参数is_debug,默认值为False,然后对gradient_descent()进行修改,让其当is_debug为True时走Debug的求梯度的方法,反之走梯度公式的方法:
# 实现批量梯度下降法 |
下面我们使用波士顿房价的数据验证一下:
import numpy as np |
可以看到我们使用Debug方式训练数据时用了2.57秒,不过求了准确合理的梯度。然后用梯度公式法训练了数据,耗时242毫米,但结果相同,说明梯度计算的没有问题。
申明:本文为慕课网liuyubobobo老师《Python3入门机器学习 经典算法与应用》课程的学习笔记,未经允许不得转载。