这篇笔记主要介绍线性回归算法,对在第一篇笔记中介绍过的线性回归算法进行实现。kNN算法主要解决的是分类问题,并且它的结果不具备良好的解释性。线性回归算法主要解决回归问题,它的结果具有良好的可解释性,和kNN算法的介绍过程一样,线性回归算法也蕴含了机器学习中很多重要的思想,并且它是许多强大的非线性模型的基础。
简单线性回归
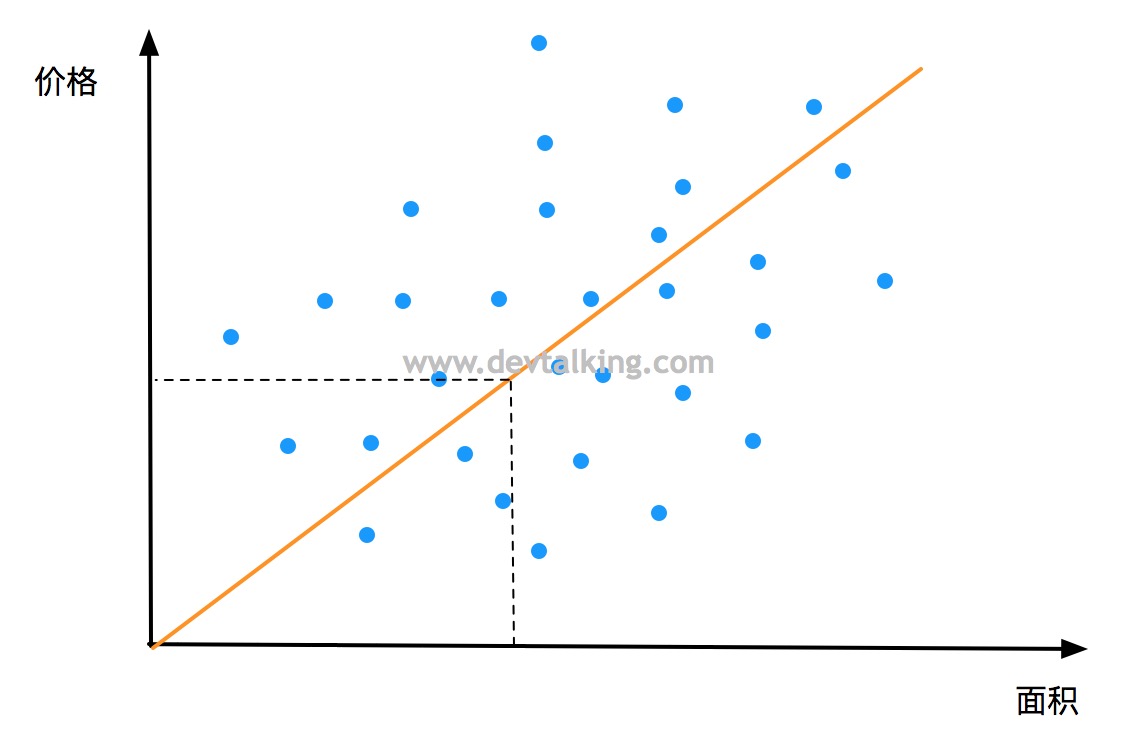
在第一篇笔记中,我们举过房屋面积大小和价格例子,将其绘制在二维坐标图上,横轴表示房屋面积,纵轴表示房屋价格,这里样本特征数据只有一个,那就是房屋面积,而在kNN算法的分类问题中,二维坐标图上横纵轴表示的都是样本特征数据,这是一个比较明显的区别。如果线性回归问题要在图中表示两种样本特征数据的话就需要三维空间坐标来表示。我们一般将只有一种样本特征数据的线性回归问题称为简单线性回归问题。
回顾线性回归
线性回归其实就是寻找一条直线,最大程度的拟合样本特征和样本输出标记之间的关系。
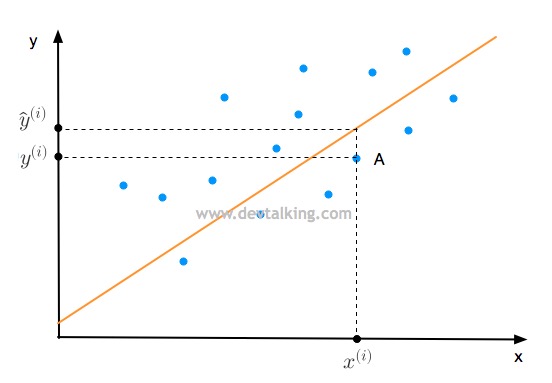
我们来看上面这张图,大家知道直线的方程是$y=ax+b$,那么点A肯定是在一条直线上,该条直线方程为$y^{(i)}=ax^{(i)}+b$,那么点A的横轴值为$x^{(i)}$,既是A的样本特征值,纵轴值为$y^{(i)}$,既是A的样本输出值。我们假设图中的红线就是拟合直线,方程为$\hat y^{(i)}=ax^{(i)}+b$,也就是将$x^{(i)}$代入这条红线,会得到一个预测的纵轴值$\hat y^{(i)}$。我们希望真值$y^{(i)}$和预测值$\hat y^{(i)}$的差值越小,说明我们的拟合直线拟合的越好。
因为差值有正有负,为了保证都是正数,所以将差值进行平方,之所以不用绝对值,是为了方便求导数。
方程求导的知识可参阅 《机器学习笔记一之机器学习定义、导数、最小二乘》 。
$$ (y^{(i)} - \hat y^{(i)})^2 $$
将所有样本特征都考虑到,既将所有真值和预测值的差值求和:
$$ \sum_{i=1}^m(y^{(i)} - \hat y^{(i)})^2 $$
将$ax^{(i)}+b$代入上面的公式就得到:
$$\sum_{i=1}^m(y^{(i)} - ax^{(i)}-b)^2$$
上面的公式我们称为损失函数(Loss Function),损失函数值越小,我们的拟合直线越好。在Loss函数中,$a$和$b$是变量,所以我们要做的就是找到使Loss函数值最小的$a$和$b$。这个套路是近乎所有参数学习算法常用的套路,既通过分析问题,确定问题的损失函数,通过最优化损失函数获得机器学习的模型。像线性回归、多项式回归、逻辑回归、SVM、神经网络等都是这个套路。