NumPy
NumPy是Python中的一个类库,它支持高阶维度数组(矩阵)的创建及各种操作、运算,是我们在机器学习中经常会使用的一个类库。这一节再看一些NumPy的矩阵用法。
numpy.random
NumPy也提供了生成随机数和随机元素数组的方法,我们来看一下:
# 生成从0到10之间的随机数 |
如果我们希望每次使用随机方法生成的结果都是一样的,一般调试时候有这个需求,此时NumPy的random()方法也提供了方便简单的方式,既随机种子的概念:
# 生成随机矩阵前给定一个种子 |
指定均值和标准差生成随机数数组或矩阵
我们先来看看均值、方差、标准差的概念。均值很好理解,就是所有样本数据的平均值,描述了样本集合的中间点:
$$ \overline X=\frac{\sum_{i=1}^nX_i}n $$
方差是衡量样本点和样本期望值相差的度量值:
$$ S^2 = \frac{\sum_{i=1}^n(X_i-\overline X)^2} n $$
标准差描述的是样本集合的各个样本点到均值的距离之平均:
$$ S = \sqrt {\frac{\sum_{i=1}^n(X_i-\overline X)^2} n } $$
标准差也就是对方差开根号。举个例子,[0, 8, 12, 20]和[8, 9, 11, 12],两个集合的均值都是10,但显然两个集合的差别是很大的,计算两者的标准差,前者是8.3后者是1.8,显然后者较为集中,标准差描述的就是这种散布度或者叫做波动大小。综上,方差的意义在于描述随机变量稳定与波动、集中与分散的状况。标准差则体现随机变量取值与其期望值的偏差。
NumPy也提供了指定均值和标准差生成随机数的方法,我们来看一下:
# 第一个参数是均值,第二个参数是标准差 |
查看数组维度
# 生成10个元素的一维数组和3行5列的矩阵 |
numpy.array的数据访问
# 一维数组访问第1个元素 |
切片
Python中,有一个获取数组片段非常方便的方法,叫做切片,numpy.array中同样支持切片,我们来看一下:
# 获取x数组中从第1个元素到第5个元素的片段 |
一般将高维矩阵降为低维矩阵其实也是使用切片来处理:
# 取X矩阵所有行的第一列 |
另外需要注意的是通过切片获取NumPy的数组或者矩阵的子数组,子矩阵是通过引用方式的,而Python中的数组通过切片获取的子数组是拷贝方式的。NumPy主要是考虑到性能效率问题。我们来看一下:
# 取X矩阵的前2行,前3列作为子矩阵 |
改变数组维度
NumPy也提供了修改数组维度的方法,我们来看看:
# x是一个一维数组 |
数组合并操作
NumPy也提供两个数组合并的操作:
x = np.arange(5) |
多维数组也支持合并:
# 2行3列的矩阵 |
上面的示例都是同维度的数组进行合并,那么不同维度的数组如何合并呢,我们来看一下:
# z为一个一维数组 |
其实NumPy提供了更智能的不同维度数组合并的方法,我们来看一下:
# 按垂直方向合并 |
数组分割操作
有合并自然就会有分割,我们来看看NumPy提供的分割方法:
x = np.arange(10) |
和合并一样,分割也有更快接的方法:
# 按垂直方向分割,既按行分割 |
矩阵运算
NumPy中提供了完整的矩阵的运算,我们从加减法来看一下:
# A为一个2行5列的矩阵 |
下面我们再来看看数乘:
# 矩阵乘常数 |
我们再来看看矩阵的转置:
A.T |
聚合操作
NumPy中有很多对数组的聚合操作方法,我们先来看看一维数组:
# 随机取10个元素的 一维数组 |
我们再来看看矩阵的聚合操作:
# X为2行3列的矩阵 |
索引和排序的相关操作
NumPy提供了一系列对数组索引操作的方法,我们来看一下:
# 随机一维数组 |
我们再来看看排序:
# 对x进行排序 |
NumPy的Fancy Indexing
一般情况下我们访问NumPy数组的数据,可以使用索引,甚至可以用步长来取:
x = np.arange(16) |
但是有时候我们需要取数组中没有什么规律的元素,比如元素之间步长不等的,这就需要用到NumPy提供的Fancy Indexing机制来获取了:
# 将我们需要访问的索引生产一个数组,然后将索引数组传入x数组 |
除了使用指定索引以外,我们还可以使用布尔数组或者矩阵来使用Fancy Indexing,我们来看一下:
X |
Matplotlib
在Python中,除了有NumPy这种对数组操作的类库,还有一个类一个在机器学习中使用比较广泛的类库是Matplotlib,这是一个绘制二维图像的类库,我们来看一下:
# 首先导入matplotlib的类库 |
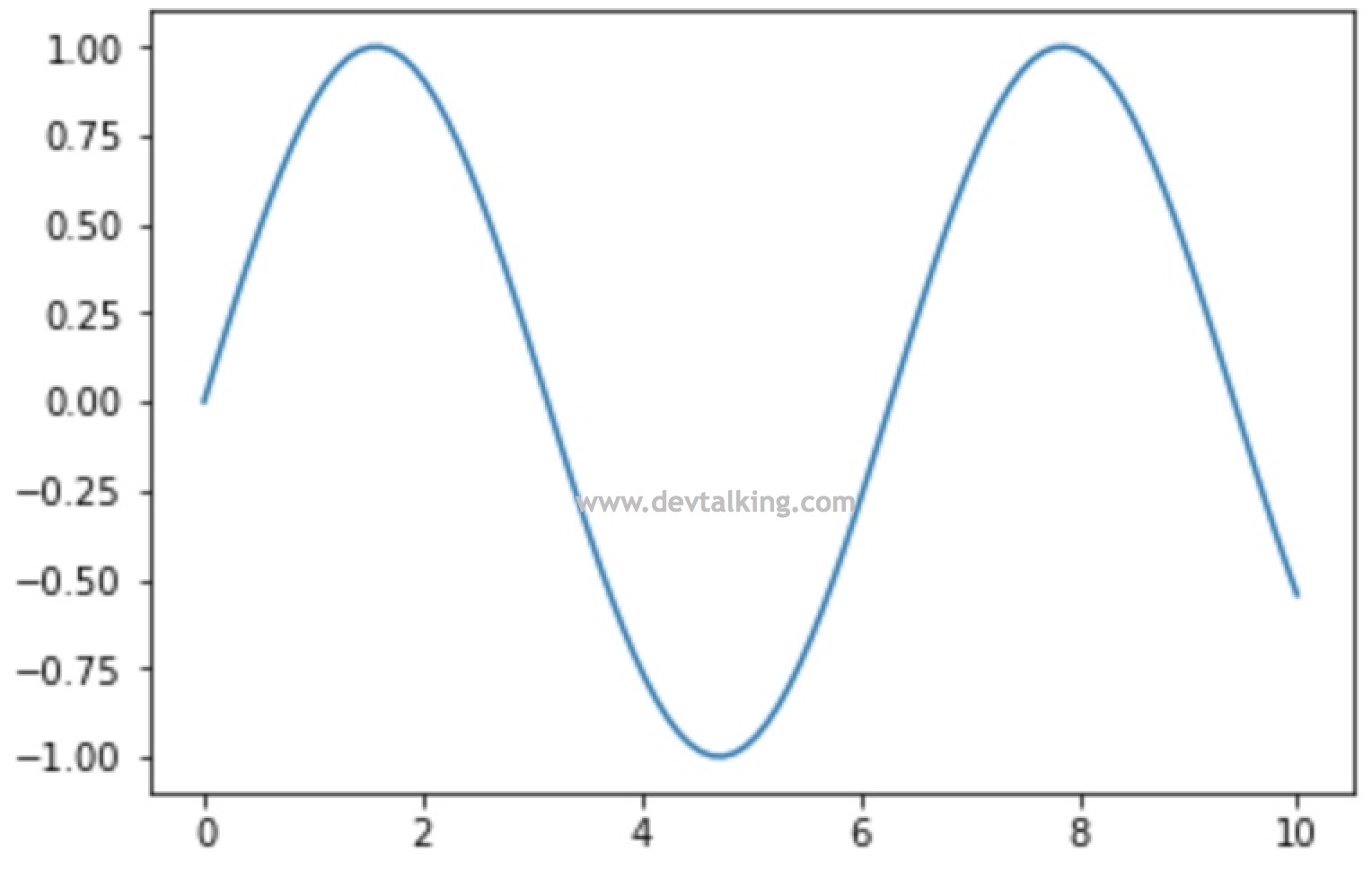
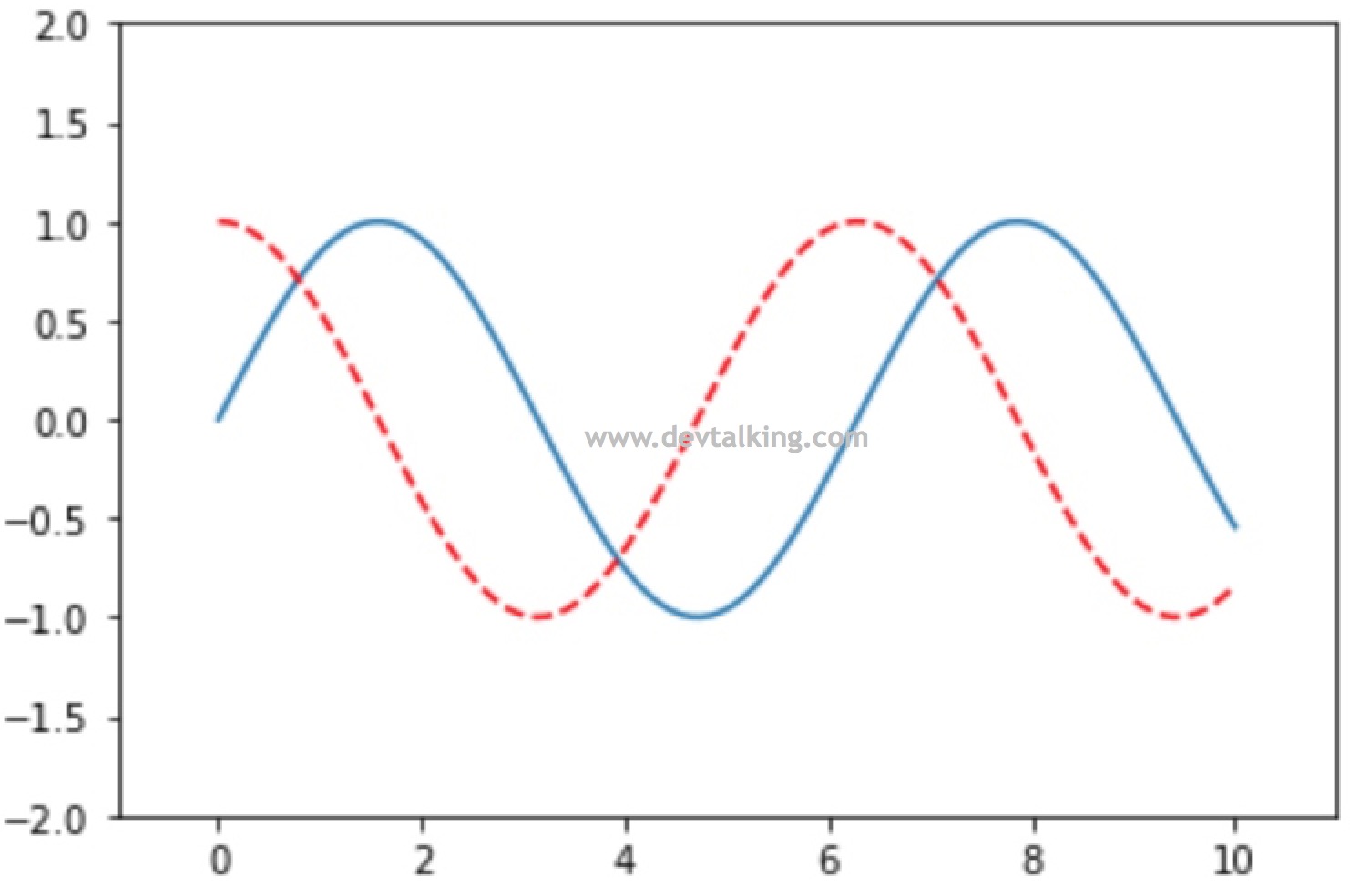
# 可以同时绘制两条线 |
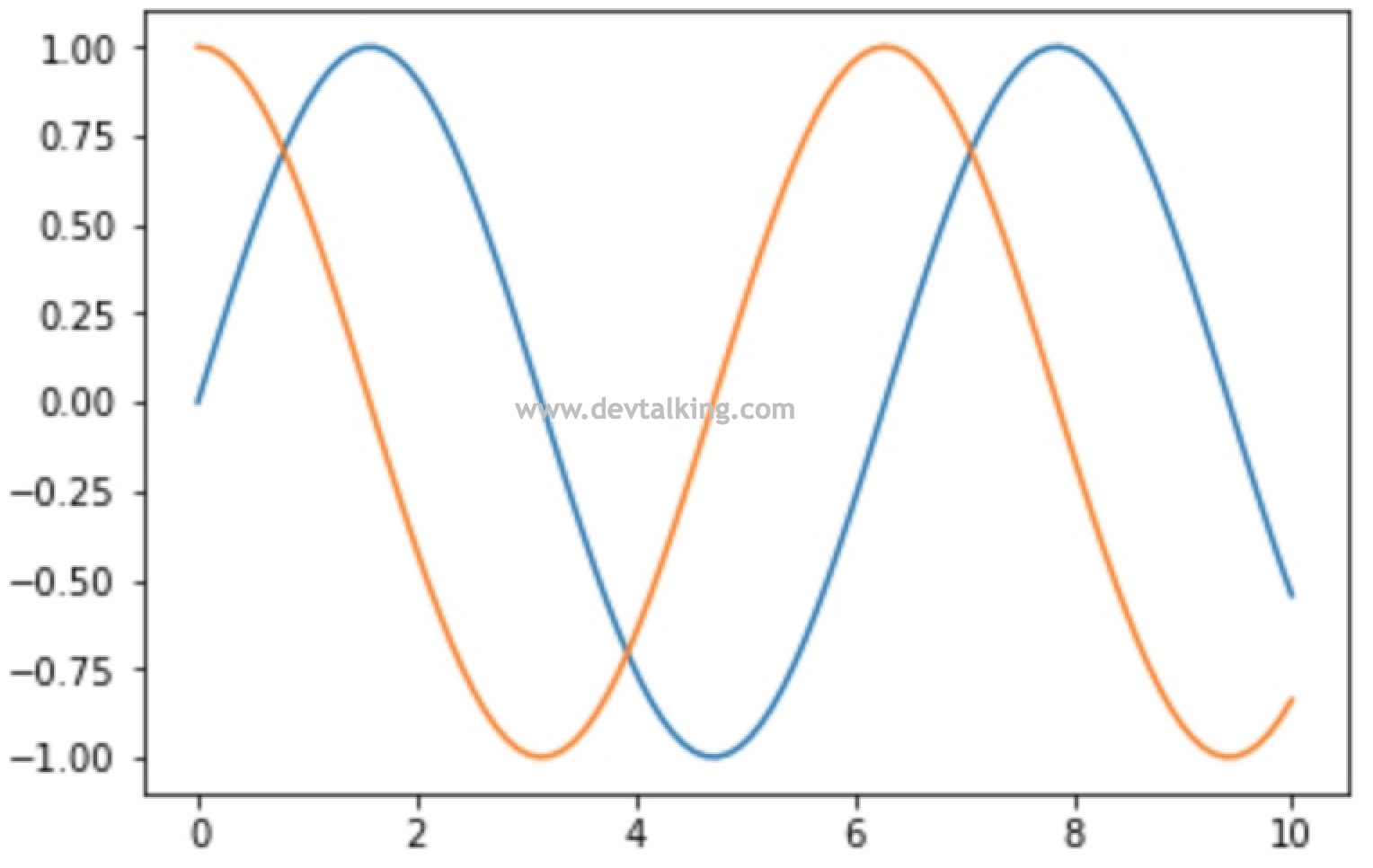
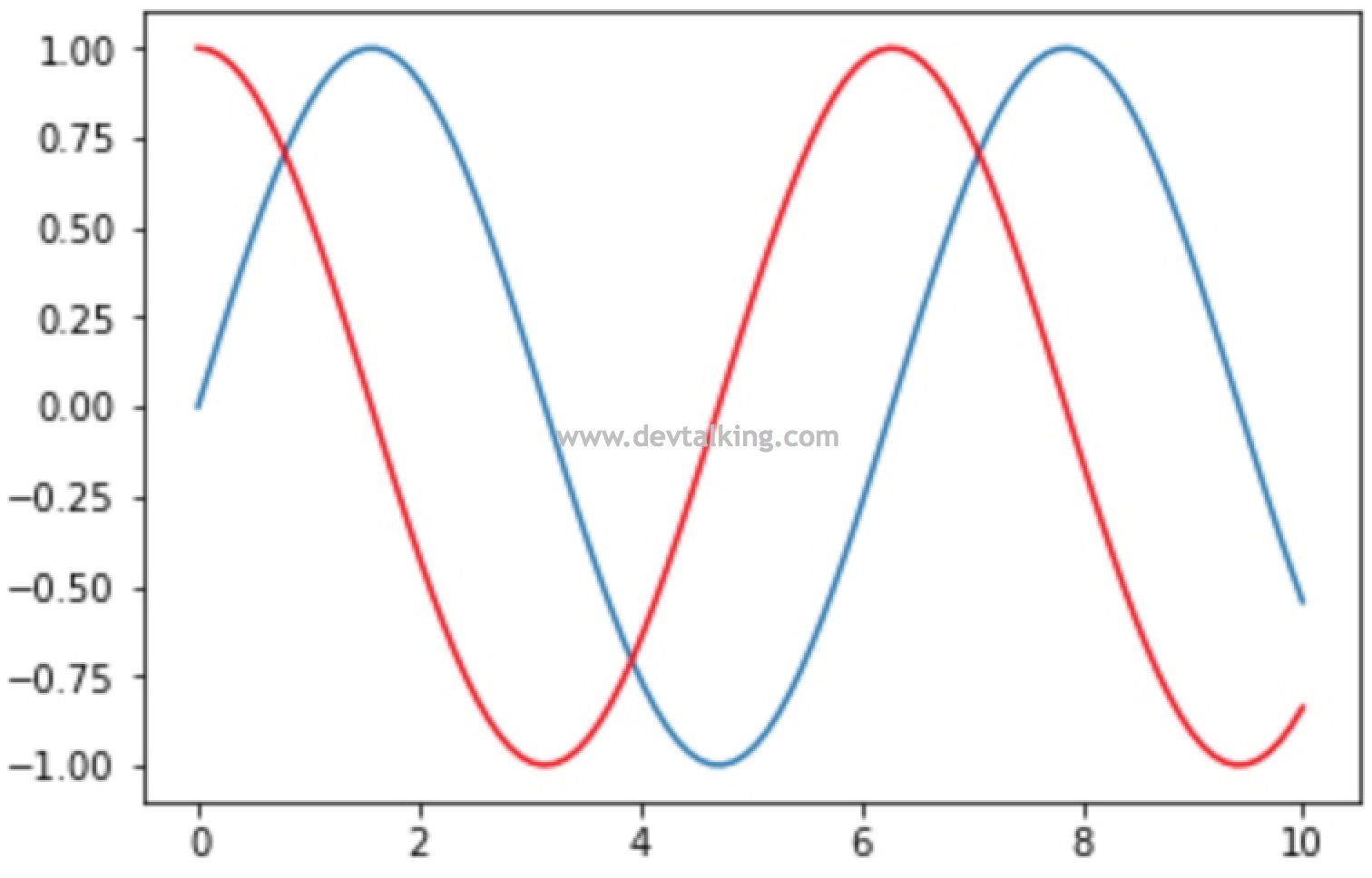
# 可以指定某条线的颜色 |
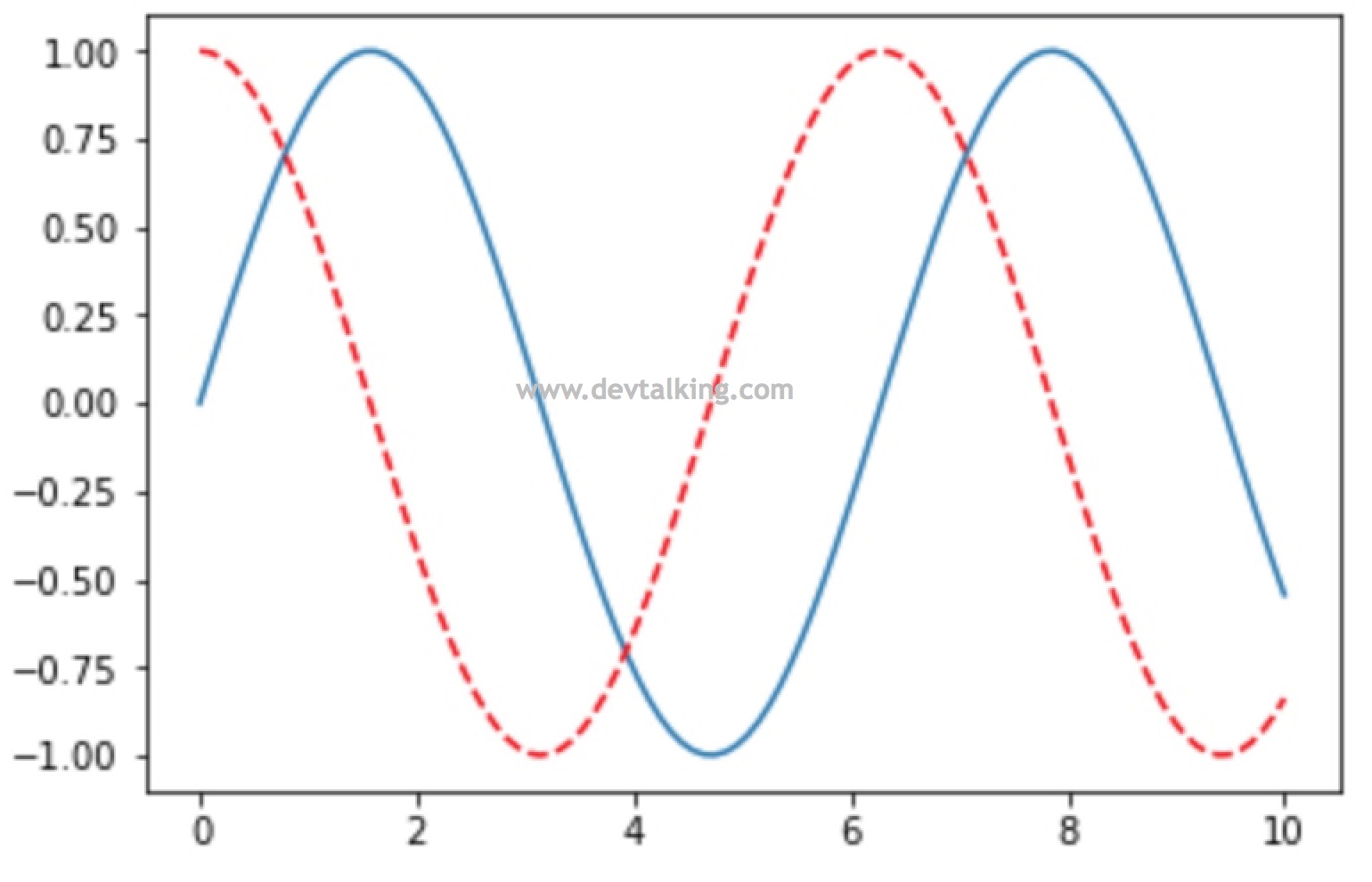
# 可以指定线的样式 |
# 可以指定x轴,y轴的区间 |
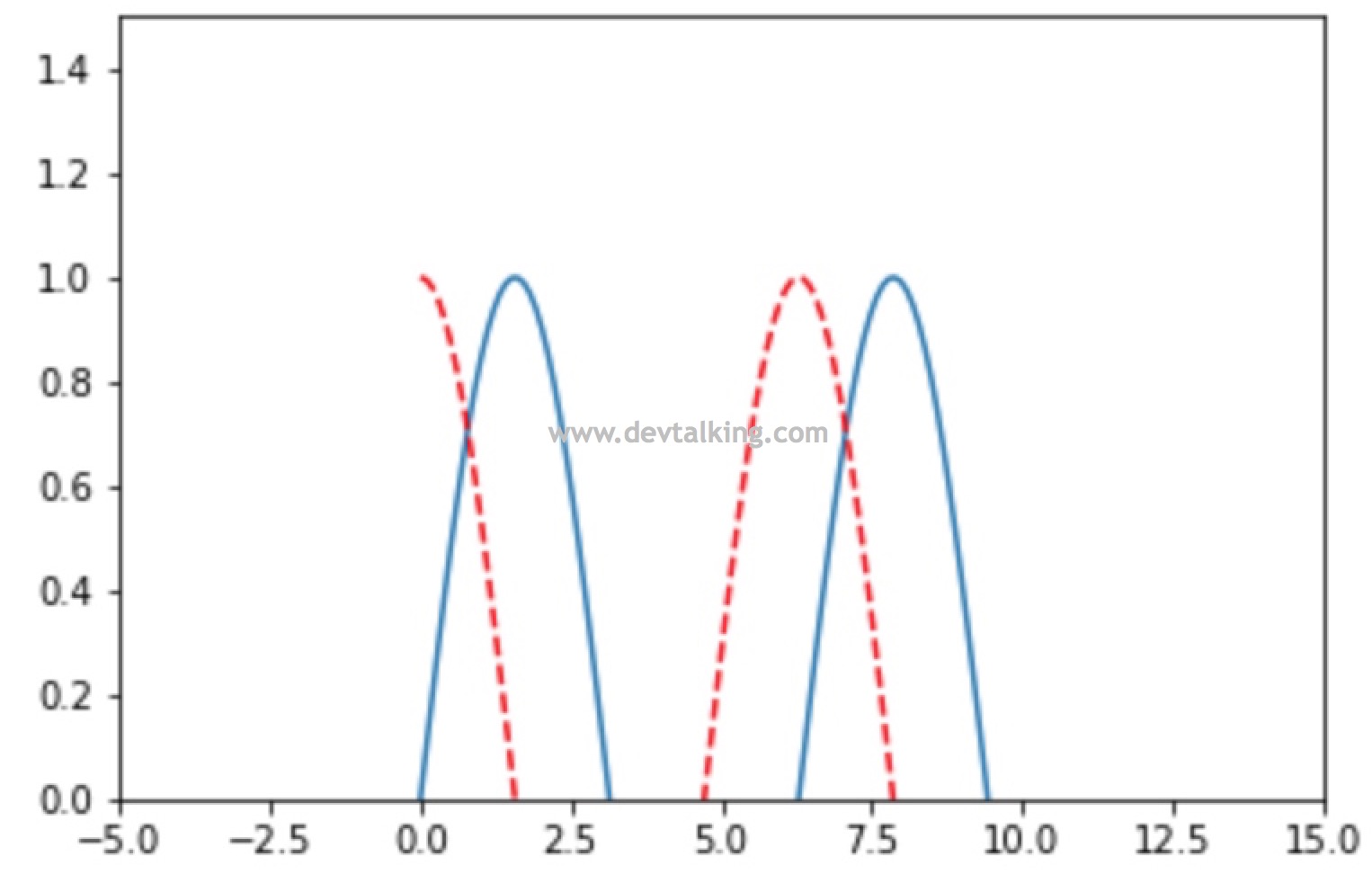
# 另一种指定x轴,y轴区间的方法 |
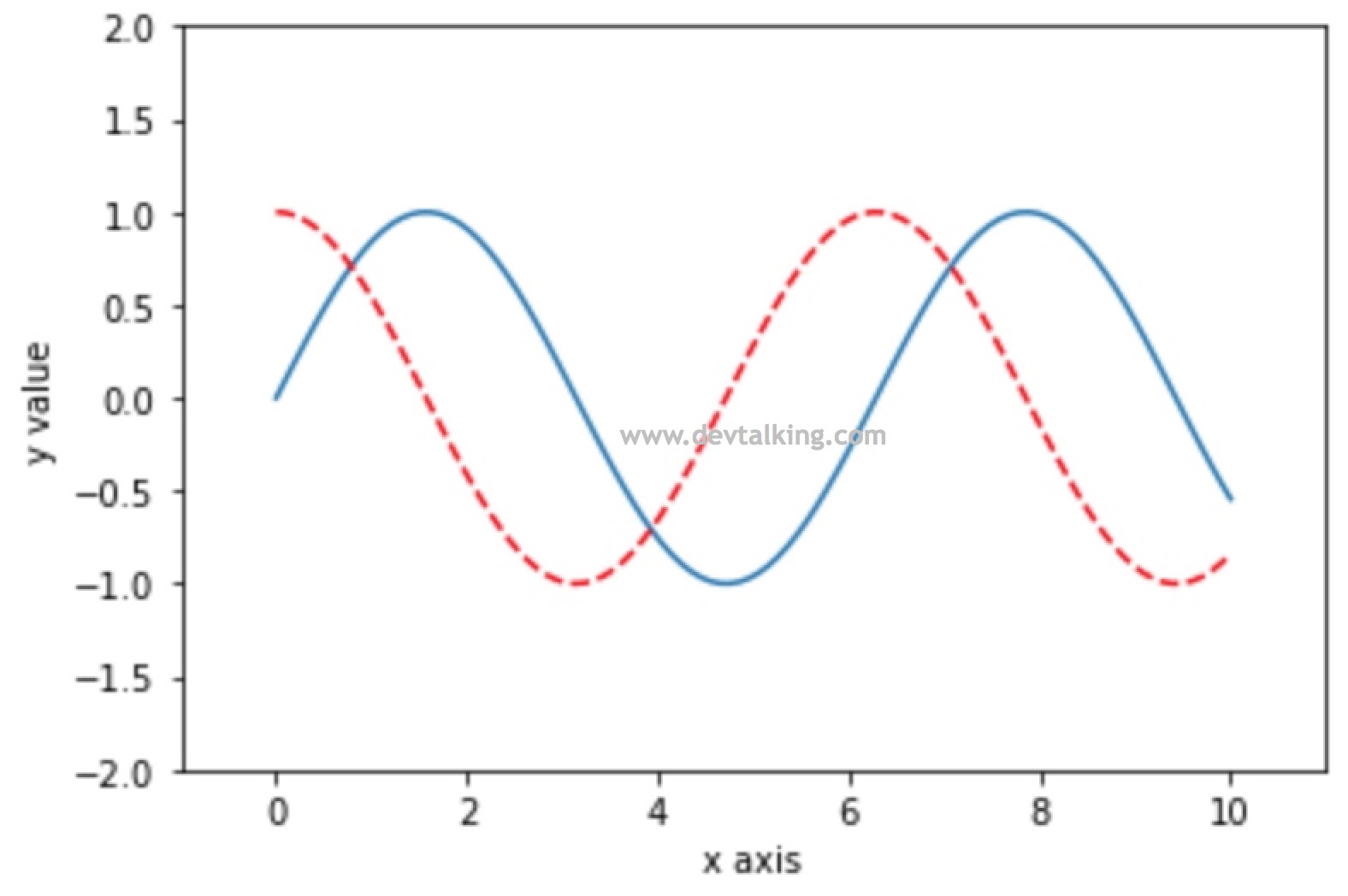
# 给x轴和y轴加说明 |
# 加图例 |
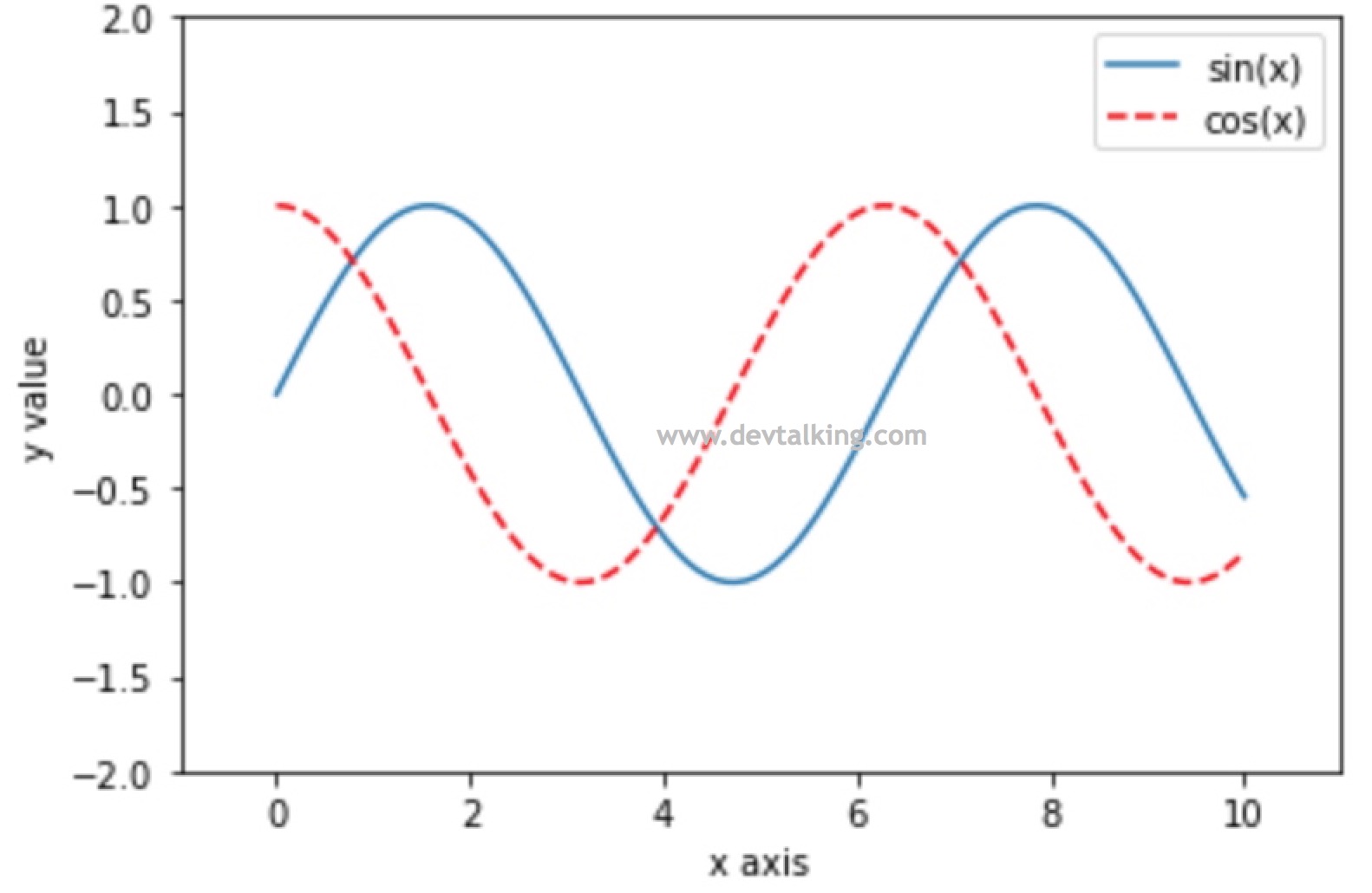
# 加标题 |
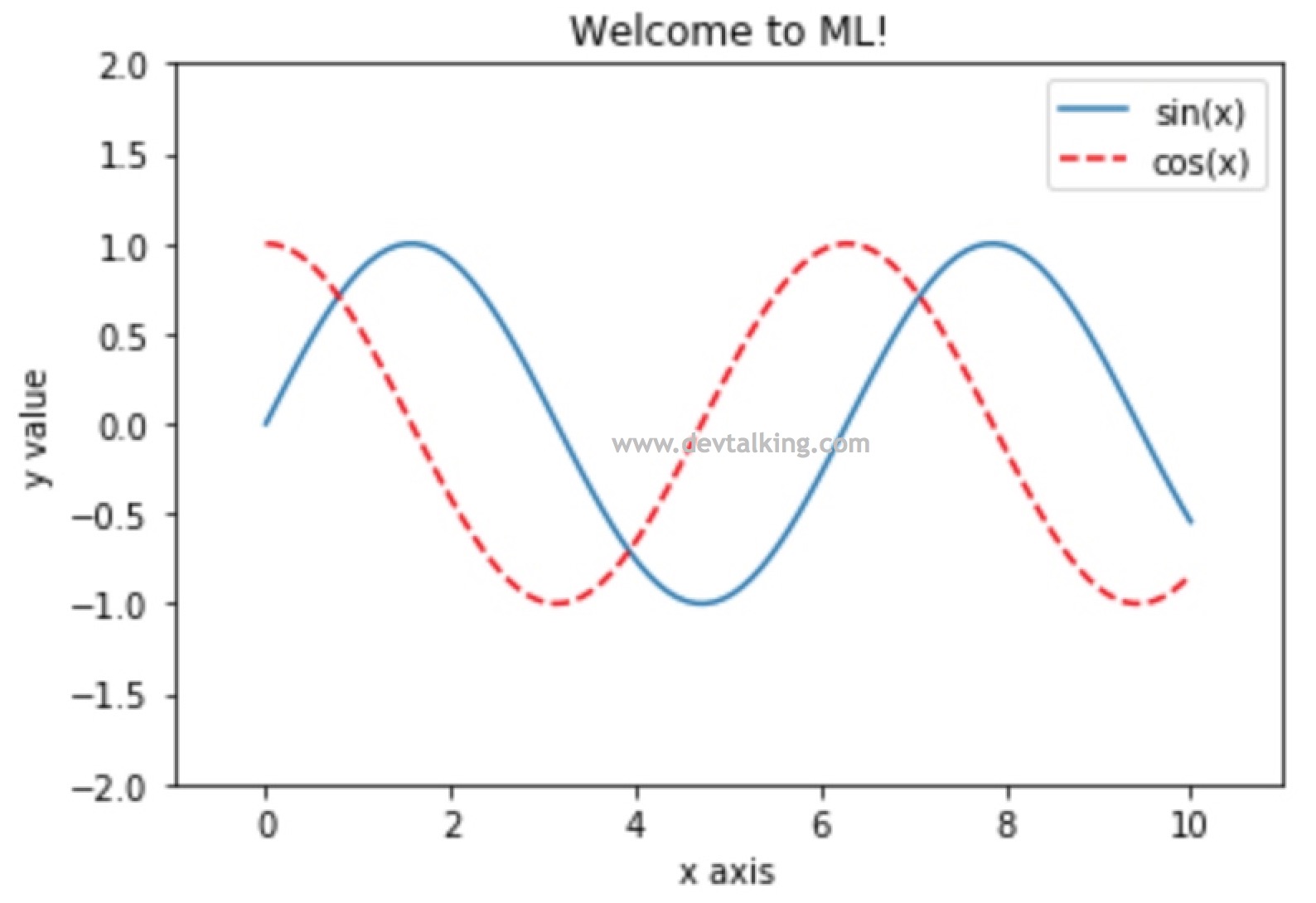
以上都是利用matplotlib画折线图,下面来看看如何画散点图:
plt.scatter(x, siny) |
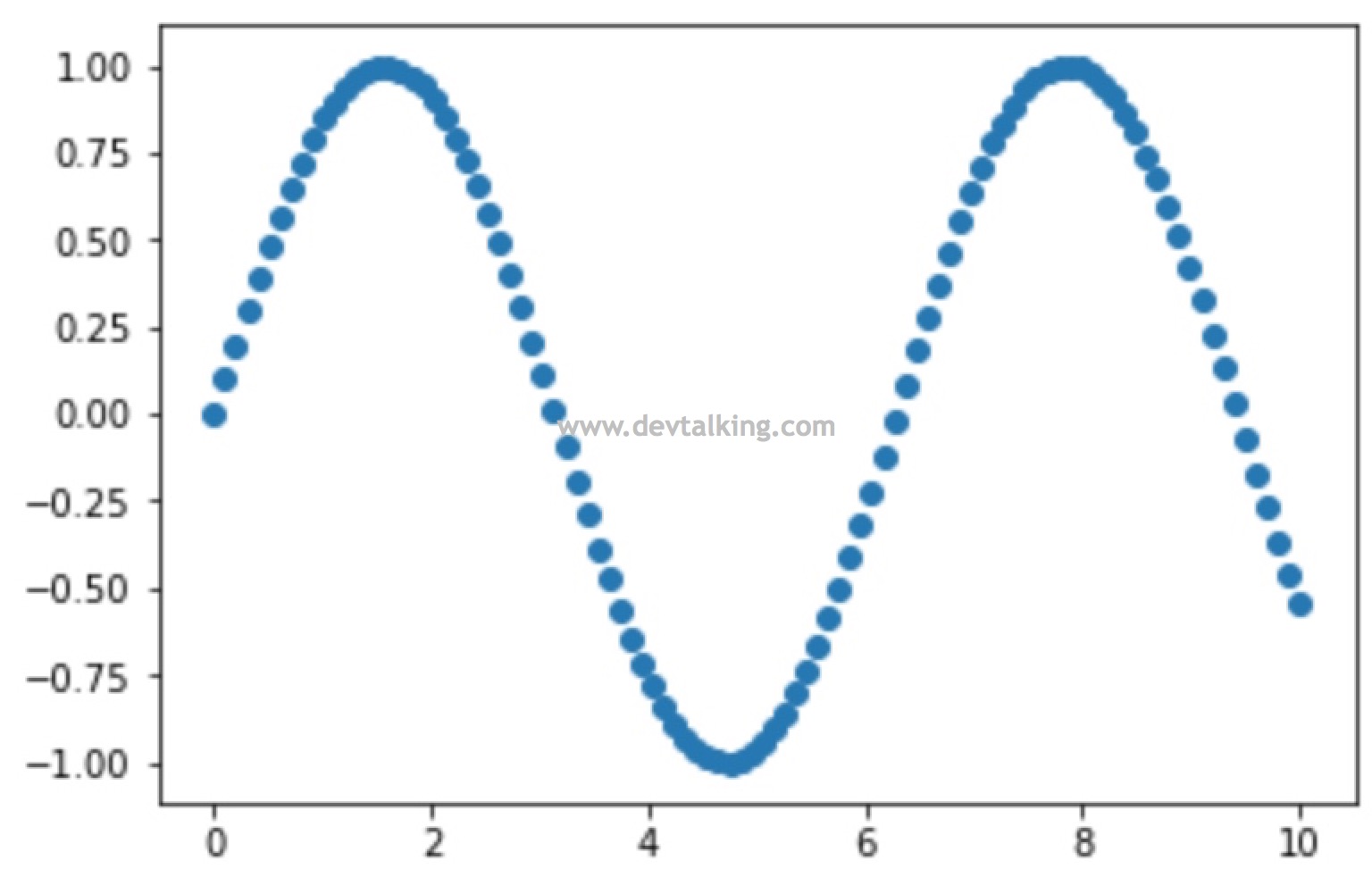
plt.scatter(x, siny) |
x = np.random.normal(0, 1, 100) |
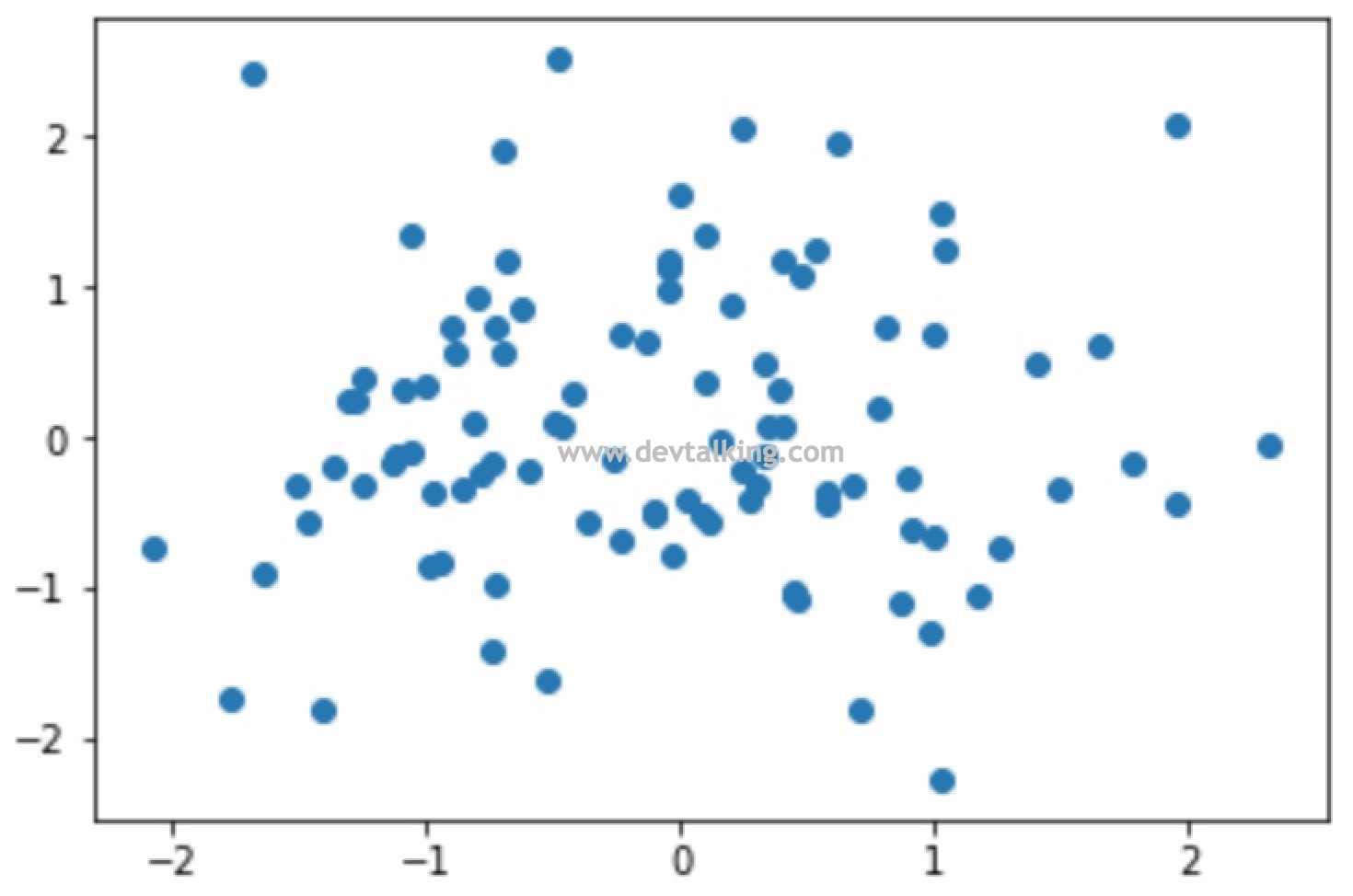
# 设置点的透明度 |
基于Scikit Learn的数据探索
Scikit-learn是Python语言中专门针对机器学习应用而发展起来的一款开源框架,其中有一个模块叫Datasets,它提供了机器学习的一些常用的数据集以及产生数据集的方法,比如波士顿房价数据集、乳腺癌数据集、糖尿病数据集、手写字体数据集、鸢尾花数据集等等。这一小节我们就通过Scikit Learn的Datasets来初步对机器学习的数据进行探索。
我们使用NumPy和Matplotlib对Scikit Learn Datasets中的鸢尾花这个数据集进行探索:
import numpy as np |
从上面的示例可以看到鸢尾花这个字典一共包含五种信息,我们逐一来看看这五种信息:
# 先看一下DESCR信息,该信息解释了鸢尾花这个数据集 |
DESCR详细的描述了鸢尾花这个数据集一共有150组数据,每组数据有4个特征,分别是萼片的长度和厚度、花瓣的长度和厚度,还有3种鸢尾花的类别以及这些数据的统计信息和详细的解释说明。
# 再来看看data |
可以看到data中的数据就是萼片长度、厚度,花瓣长度、厚度的值。是一个150行,4列的矩阵。
# feature_names的值就是4个特征的说明 |
下面我们用Matplotlib,用图将鸢尾花的数据展示出来,这样就能更直观的来分析这些数据。
# 因为matplotlib只能绘制二维图像,所以我们先来看看鸢尾花萼片的数据,取data的所有行,前2列 |
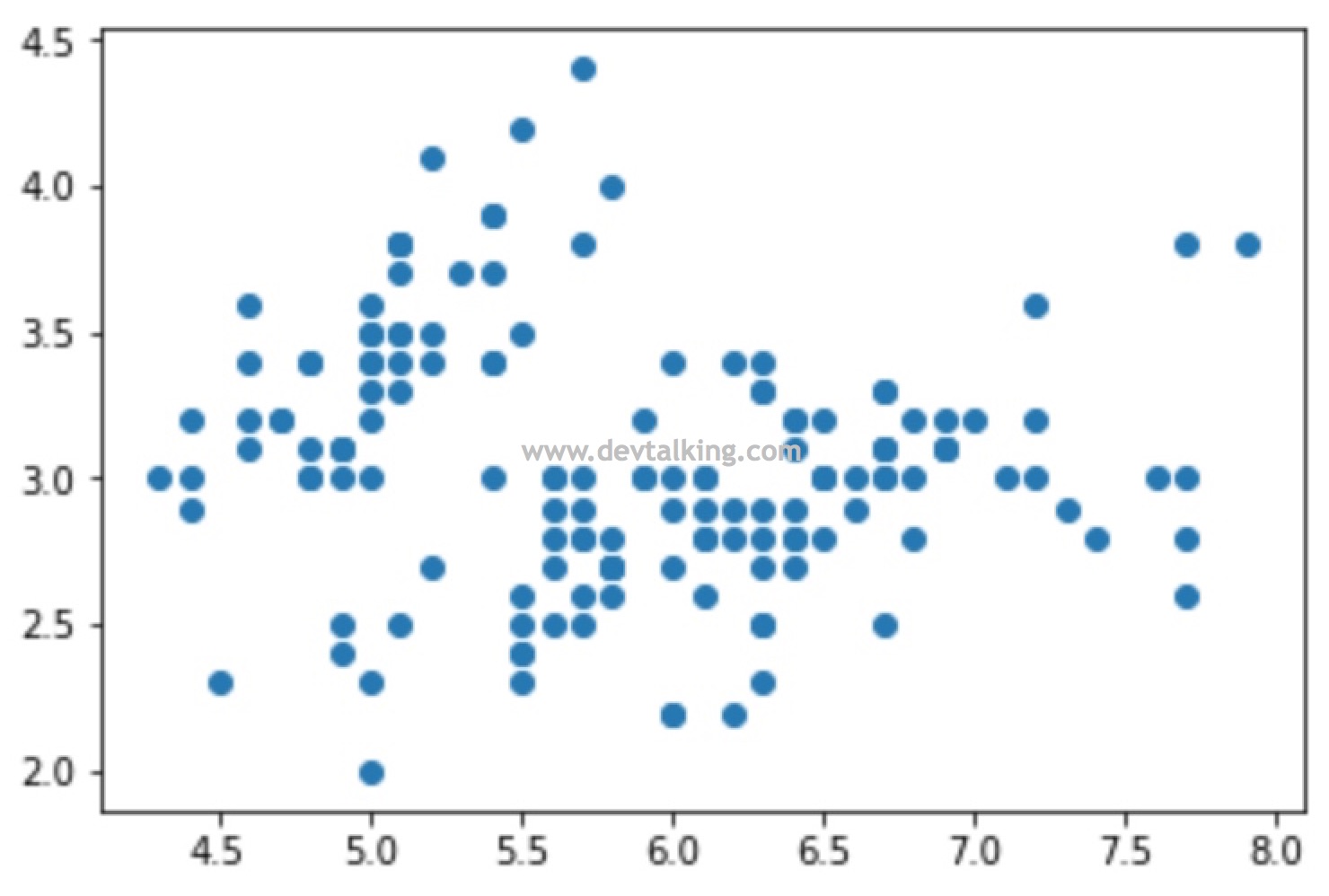
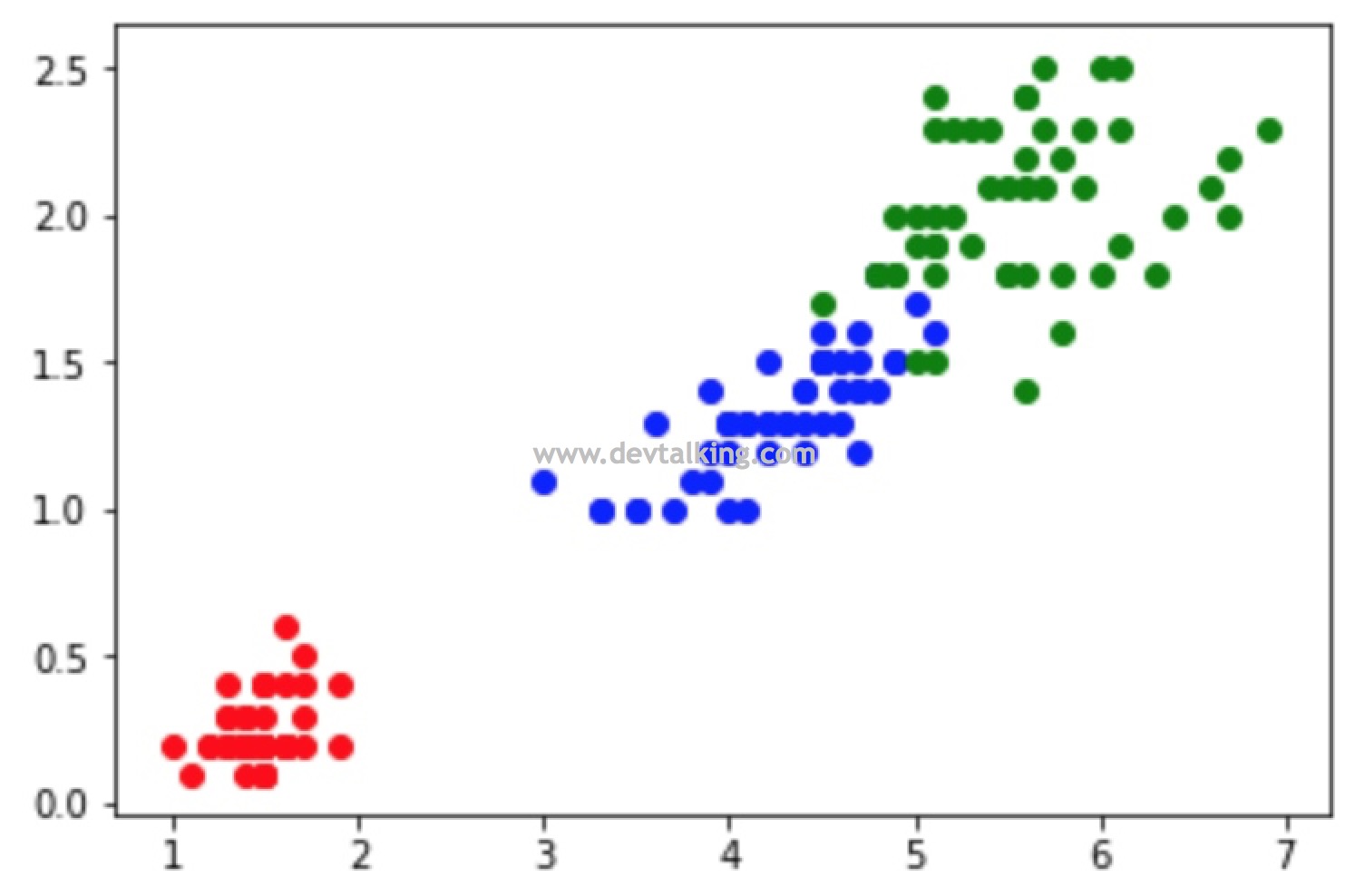
# 我们再来看看这150组鸢尾花数据从萼片维度的类别分类情况 |
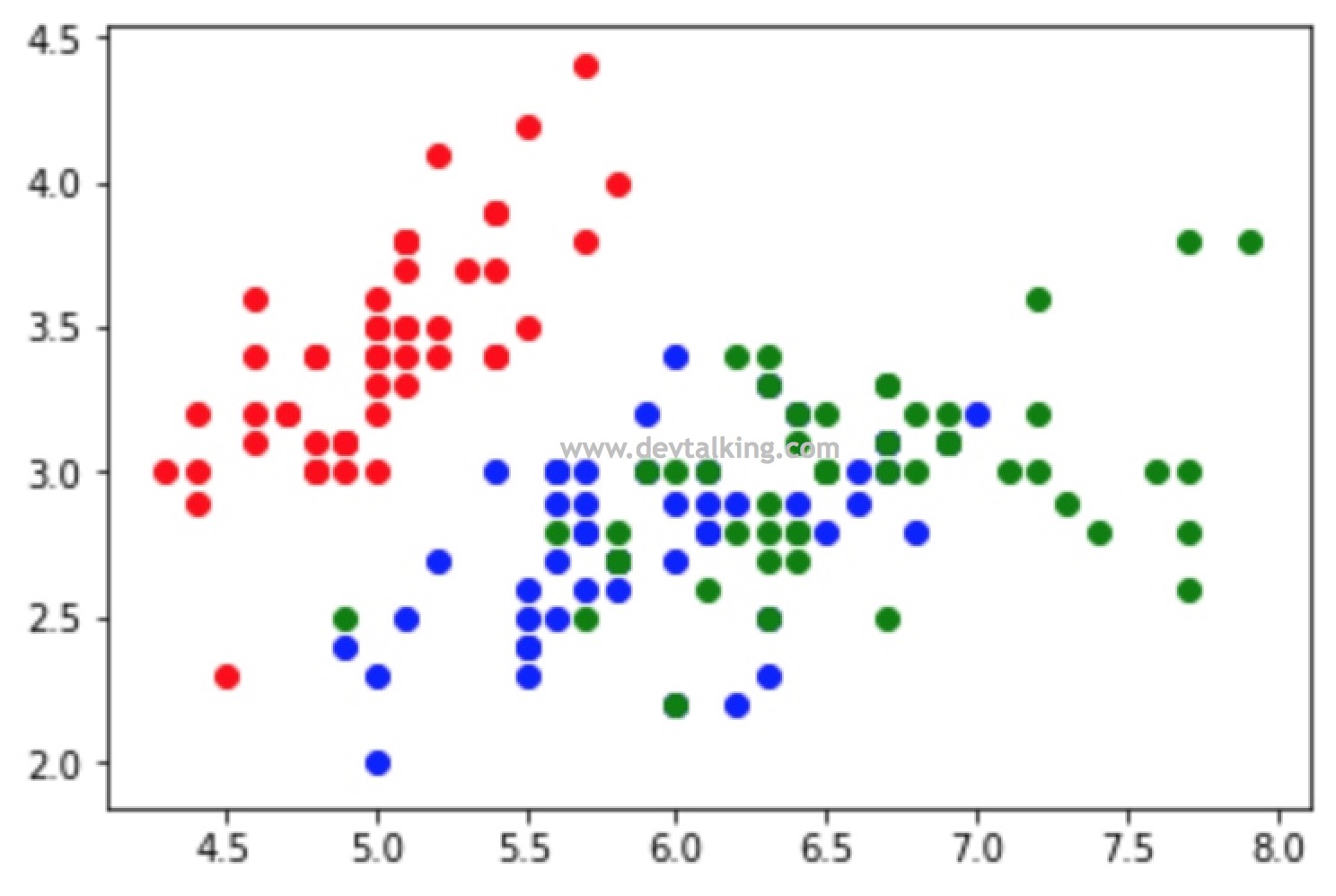
# 取data矩阵的所有行,后2列的数据,既鸢尾花的花瓣长度和宽度信息 |
# 我们再来看看这150组鸢尾花数据从花瓣维度的类别分类情况 |
kNN算法
kNN算法又称k近邻算法,是k-Nearest Neighbors的简称,该算法是监督学习中解决分类问题的算法,也是需要数据知识最少的一个算法,但是效果往往不差,能较好的解释机器学习算法使用过程中的很多细节问题,并且能很好的刻画机器学习应用的流程。
kNN算法解释
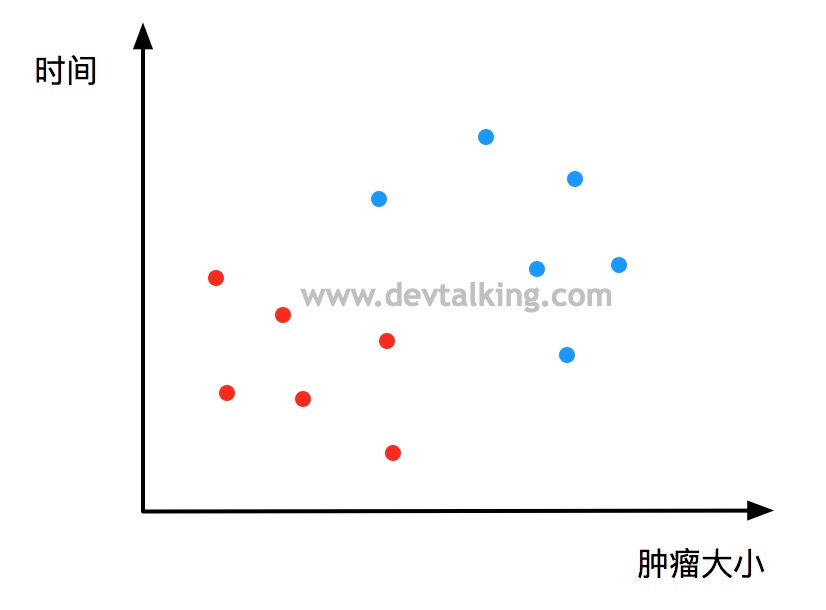
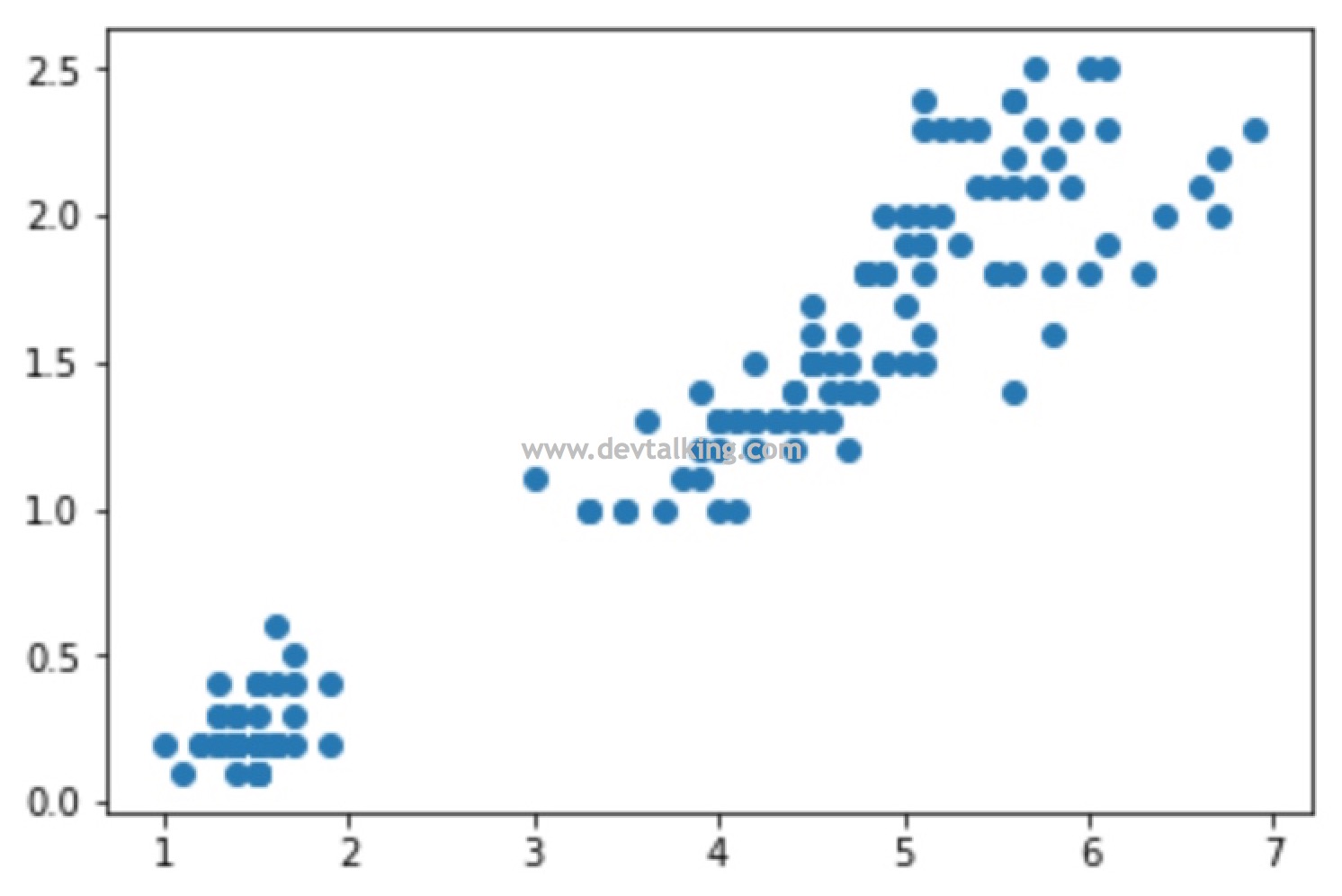
上图描述了肿瘤大小和时间的二维关系图,圆点的颜色表示肿瘤的性质是良性还是恶性。
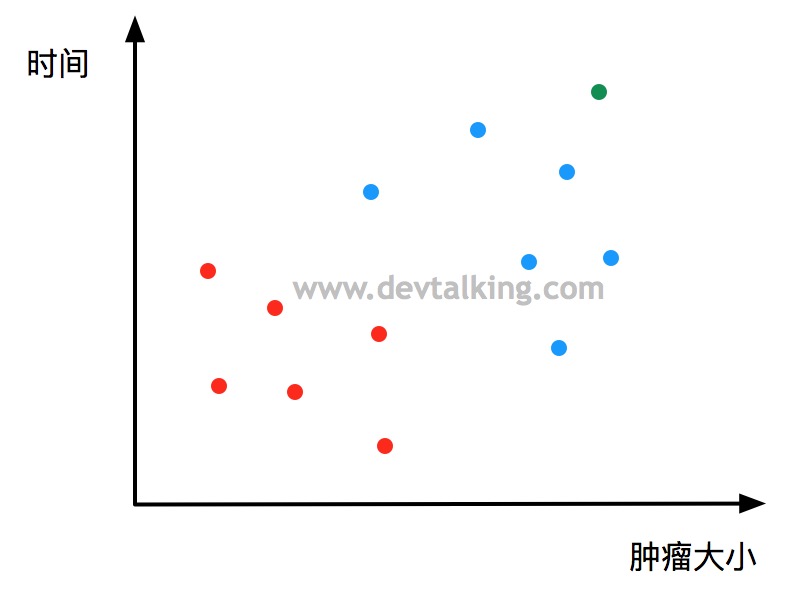
此时又有一个病人的数据采集到,那么我们如何判断这个病人的肿瘤是良性还是恶性呢?
首先我们必须取一个k值,至于这个k值是该如何取后续会讲,这里比如我们取k=3,这个k值的作用就是基于新来的这个点,找到离它最近的k个点,这里也就是找到离绿色点最近的三个点:
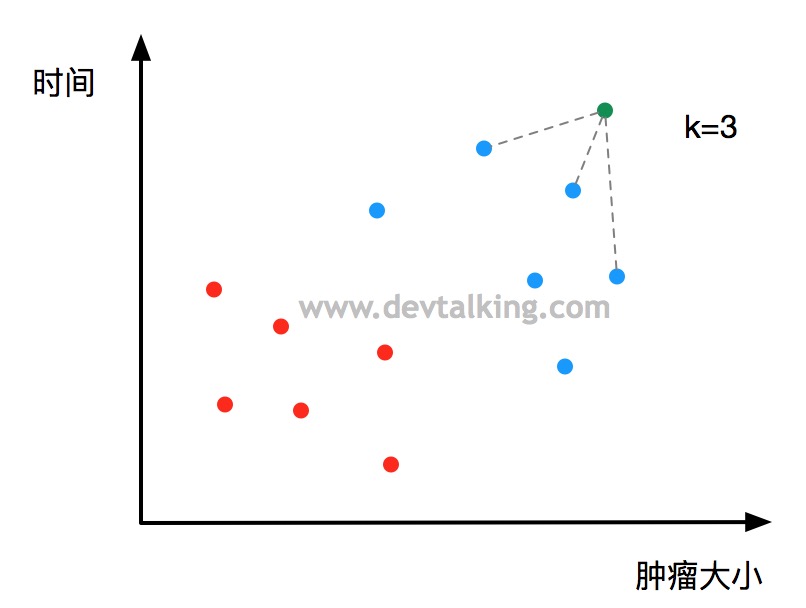
然后根据这三个代表的特征进行投票,票数最多的特征就是这个绿色点的特征,这个示例中离绿色点最近的三个点都是蓝色点,既恶性肿瘤,那么可判定绿色点代表的肿瘤性质有很高的概率也是恶性。
欧拉距离
kNN算法中唯一用到的数学知识就是如何求点与点之间的距离,在这里我们先使用最普遍的欧拉距离来进行计算,欧拉距离的公式如下:
二维:
$$ \sqrt {(x^{(a)}-x^{(b)})^2+(y^{(a)}-y^{(b)})^2} $$
三维:
$$ \sqrt {(x^{(a)}-x^{(b)})^2+(y^{(a)}-y^{(b)})^2+(z^{(a)}-z^{(b)})^2} $$
N维(N个特征):
$$ \sqrt {(x_1^{(a)}-x_1^{(b)})^2+(x_2^{(a)}-x_2^{(b)})^2+…+(x_n^{(a)}-x_n^{(b)})^2} =\sqrt {\sum_{i=1}^n(x_i^{(a)}-x_i^{(b)})^2} $$
用大白话解释就是两个点的所有相同维度之差求平方,然后全部相加再开方。有兴趣的话大家可以再深入研究一下点与点间距离的计算。
编码实现kNN算法
首先我们来准备一下数据:
import numpy as np |
我们将这些样本数据绘制出来看看:
# 和绘制鸢尾花的方式一样 |
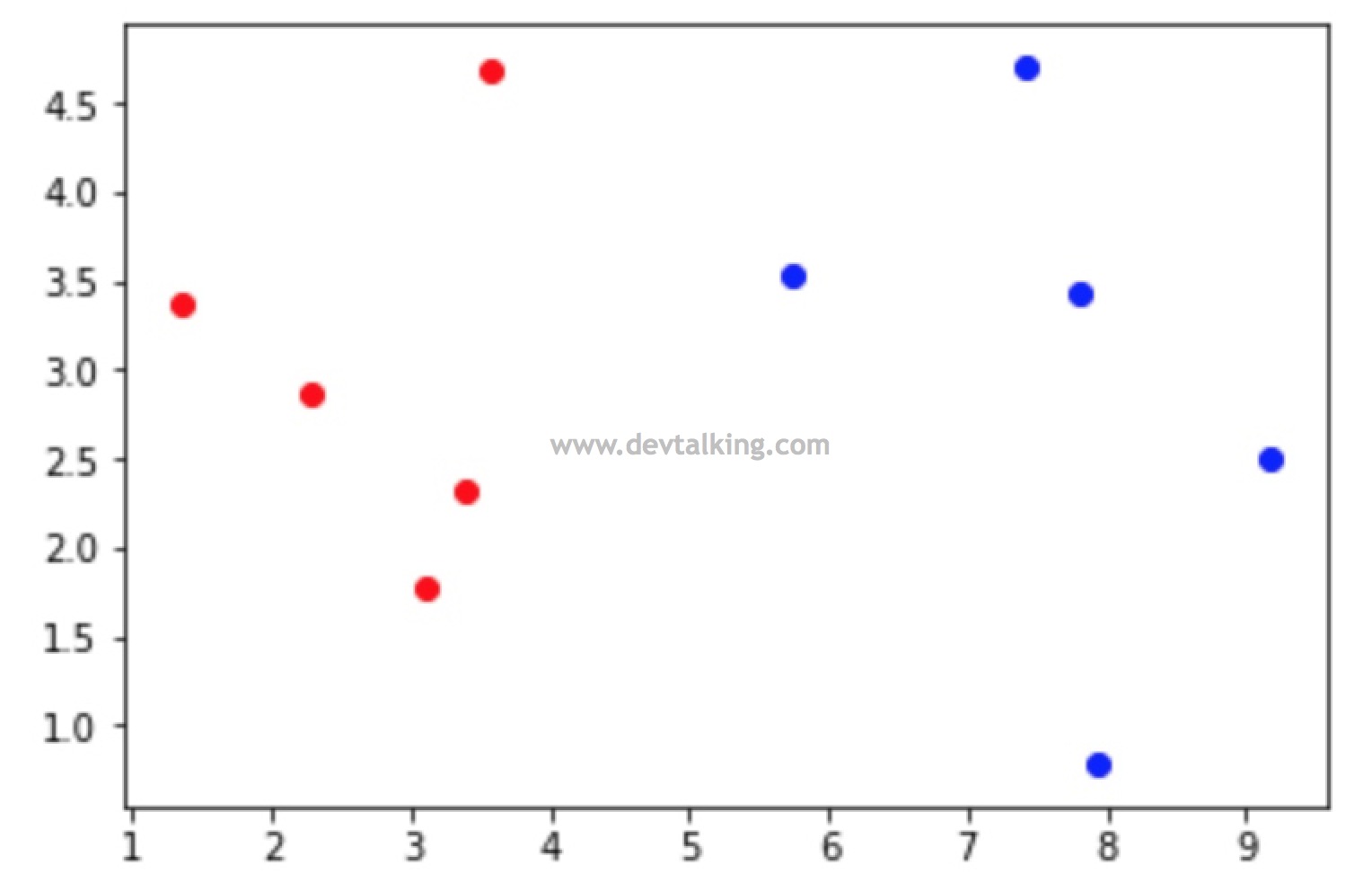
下面再创建一组数据,来模拟需要被分类的数据:
x = np.array([8.093607318, 3.365731514]) |
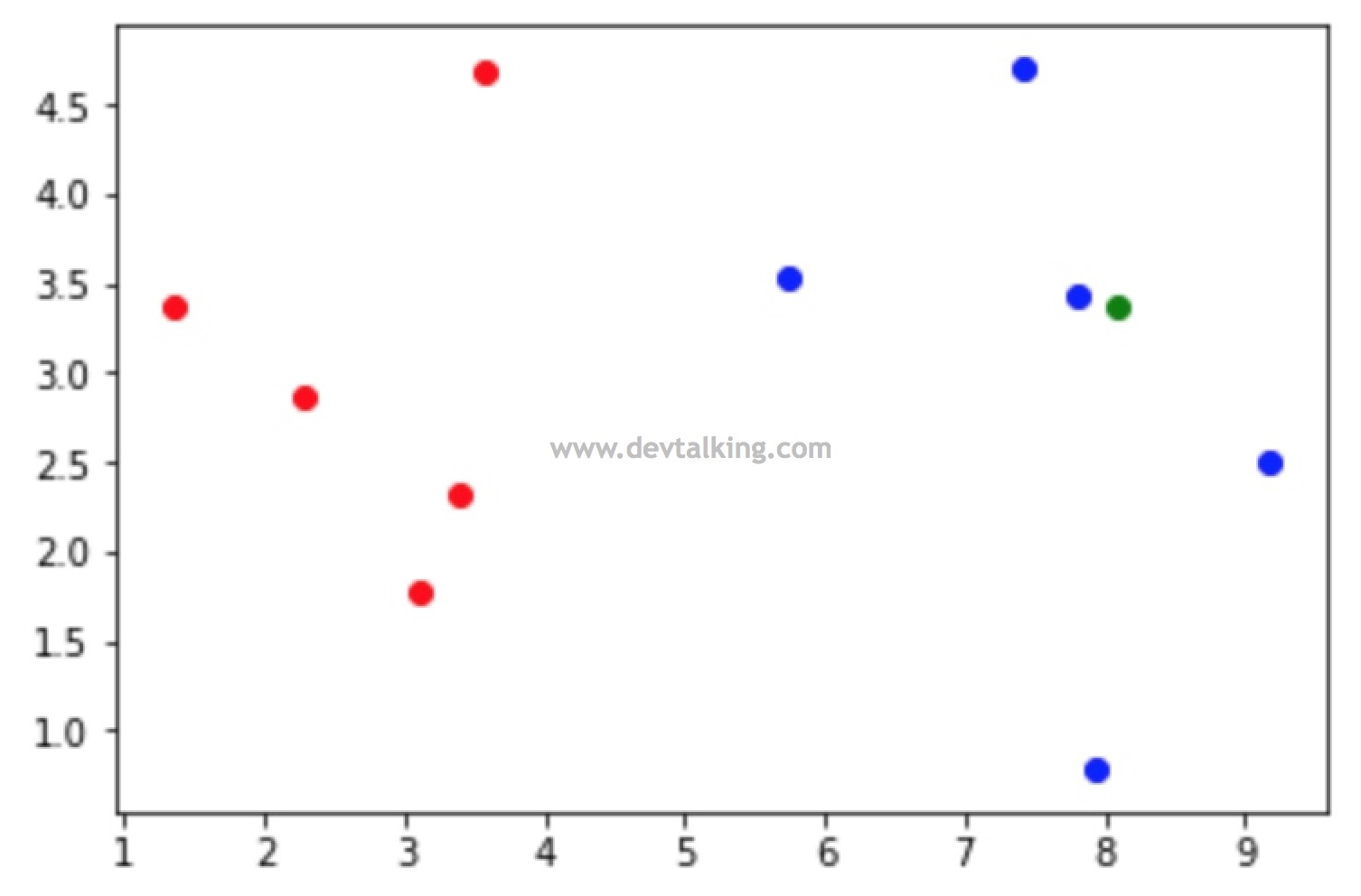
我们现在就要通过kNN算法来分析这个绿点属于哪个类别,虽然从图上我们已经可以看得出。
我们先来通过欧拉距离公式求出所有点与绿点的距离:
# 导入开方的类库 |
现在我们就求出了所有点与绿点的距离,但是求出距离并不能表示出每个距离对应点的类别,所以还需要知道这每个距离对应的是哪个点:
# 此时上文中说过的argsort方法就派上用场了 |
从上面的结果可以看到,距离绿点最近的点是X_train中的第8行样本。那么接下来我们看看如何通过k值获取这些点的类别:
# 首先定义k的值为6 |
到目前位置,我们就判断出了绿点有很大概率类别属于1,这个过程就是kNN算法的核心过程。
总结
在下一篇笔记中,将会介绍Scikit Learn中是如何封装kNN算法的,以及我们会自己封装一个kNN算法,以及对分类准确度评定,超参数,数据归一化等知识点的讲解。
申明:本文为慕课网liuyubobobo老师《Python3入门机器学习 经典算法与应用》课程的学习笔记,未经允许不得转载。