了解完Producer,接下来介绍Kafka中的Consumer的概念,以及在消费Message时有什么样的策略。
Consumer
Consumer负责从Topic中读取数据,我们已经知道了Topic是通过名称确定唯一的,所以指定Consumer从哪个Topic中读数据,同样使用Topic名称指定。Kafka中的Consumer有以下几点需要我们注意:
- 我们只需要指定需要从哪个Topic中读取数据即可。不需要关心Consumer是从哪个Broker中的哪个Partition中读数据,这些工作由Kafka帮我们处理好了。
- 当持有Topic的Broker挂掉,重新恢复后,Consumer可以自动重新从该Broker中读数据。
- 在一个Partition中,Consumer是按Offset的顺序读取数据的。
- 一个Consumer可以同时读取多个Broker中的不同Partition,但是Partition之间无法保证读取数据的顺序,因为是并行执行的。
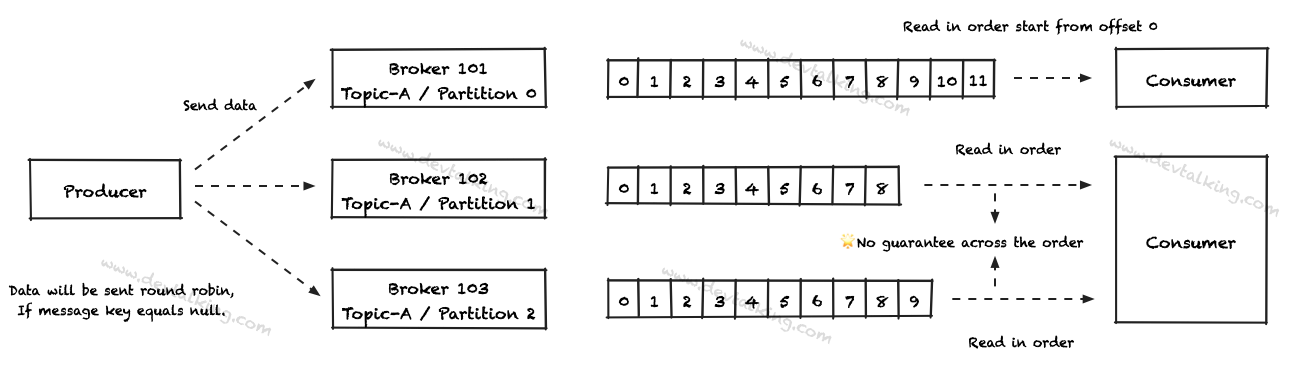
Consumer Group
Consumer有组的概念,对于Consumer Group有以下几点需要我们注意:
- 不同的Consumer Group之间可以读取相同的Partition中的数据。
- Consumer Group里的Consumer之间不能读取相同的Partition中的数据,他们读取数据的Partition是专享的。
- 所以基于上面的知识点,如果Consumer数量多于Partition数量,那么就会有Consumer处于空闲的状态。
上图的示例中,如果Consumer Group 2中再增加一个Consumer 4,那么Consumer 4就会处于空闲状态,因为没有多余的Partition分给它了。
Consumer Offset
一个优秀的MQ系统,必定会有一个能力,那就是断点续传的能力。既当Consumer挂掉再恢复后,需要从挂掉的前一时刻读数据的点开始接着往后读。那么如何做到这一点呢,那就是通过Consumer Offset来实现的。
每当一个活跃的Consumer正在从Partition中读取数据时,Kafka都会根据给定的策略记住该Consumer读取数据的Offset。这个策略就是Consumer提交Offset的策略。目前有三个策略:
At most once
这种策略下,只要Consumer读到了Message,就立即提交Offset,不考虑Message有没有被正确处理。如果Message刚读过来,还没有处理的时候,Consumer挂掉了,重新恢复后对上一次读取的Message不会重新读取,所以这种模式比较容易丢失数据。整个过程如下图所示:

At least once
这种策略下,Consumer需要读到Message,并且正确处理了Message后,才会提交Offset。如果Consumer挂掉,再恢复后,可以重新读取上一次的Message继续处理。这里就需要我们处理Message的逻辑必须是幂等的,否则会造成Message重复执行导致错误的业务结果。整个过程如下图所示:
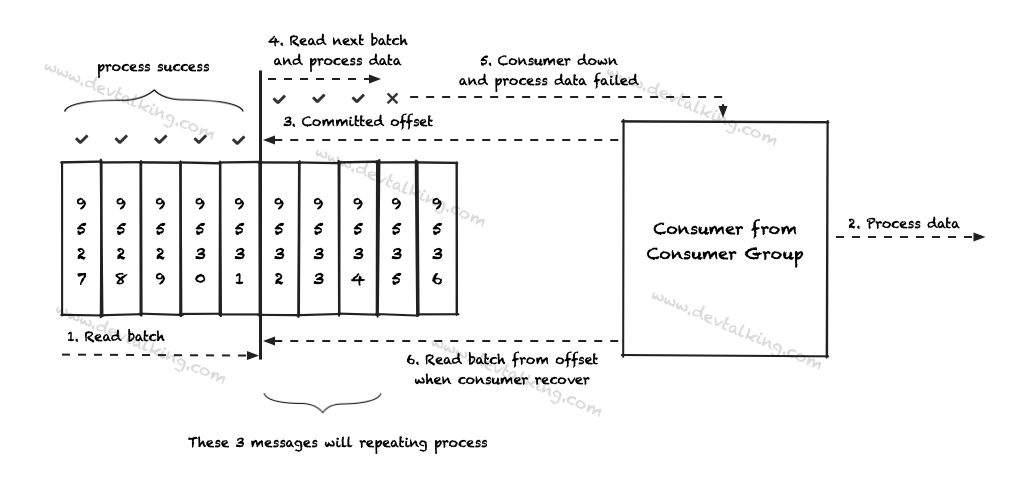
Exactly once
这个策略想做到的是不丢数据,又可以不用幂等的处理逻辑。这里通常需要Kafka和外部系统配合使用。后面再做具体介绍。
Consumer Poll Options
在Consumer订阅Topic拉取Message的行为中,会涉及到四个参数:
fetch.min.bytes:该参数表示每次拉取Message的最小量,默认是1Bytes。fetch.max.bytes:该参数表示每次拉取Message的最大量,默认是50MB。max.poll.records:该参数表示每次拉取Message的条数,默认是500条。max.partitions.fetch.bytes:该参数表示每个Partition在一次拉取中,可以被拉取到Message的最大量,默认是1MB。
这些参数可以让Consumer控制拉取Message的速率,以及可以监控Consumer每次拉取Message的具体信息。
Consumer Offset Reset Behavior
在实际应用中,Consumer是很有可能在运行过程中挂掉的,那么当Consumer重新恢复后,拉取什么范围的Message,是有策略可以设置的,可以通过设置auto.offset.reset属性,常用的值有两个:
earliest:从Message文件的最开始进行拉取,既将Topic中的所有数据重新拉取过来。latest:从Message文件的最后开始拉取,既不考虑Topic之前的所有数据,只拉取最新的数据。
在后面讲到CLI的时候,这部分再做详细阐述。
Consumer internal thread
为保证Consumer的稳定性和高可用性。Kafka有心跳机制,所以Consumer不光和Broker交互,也要和心跳监控节点交互:
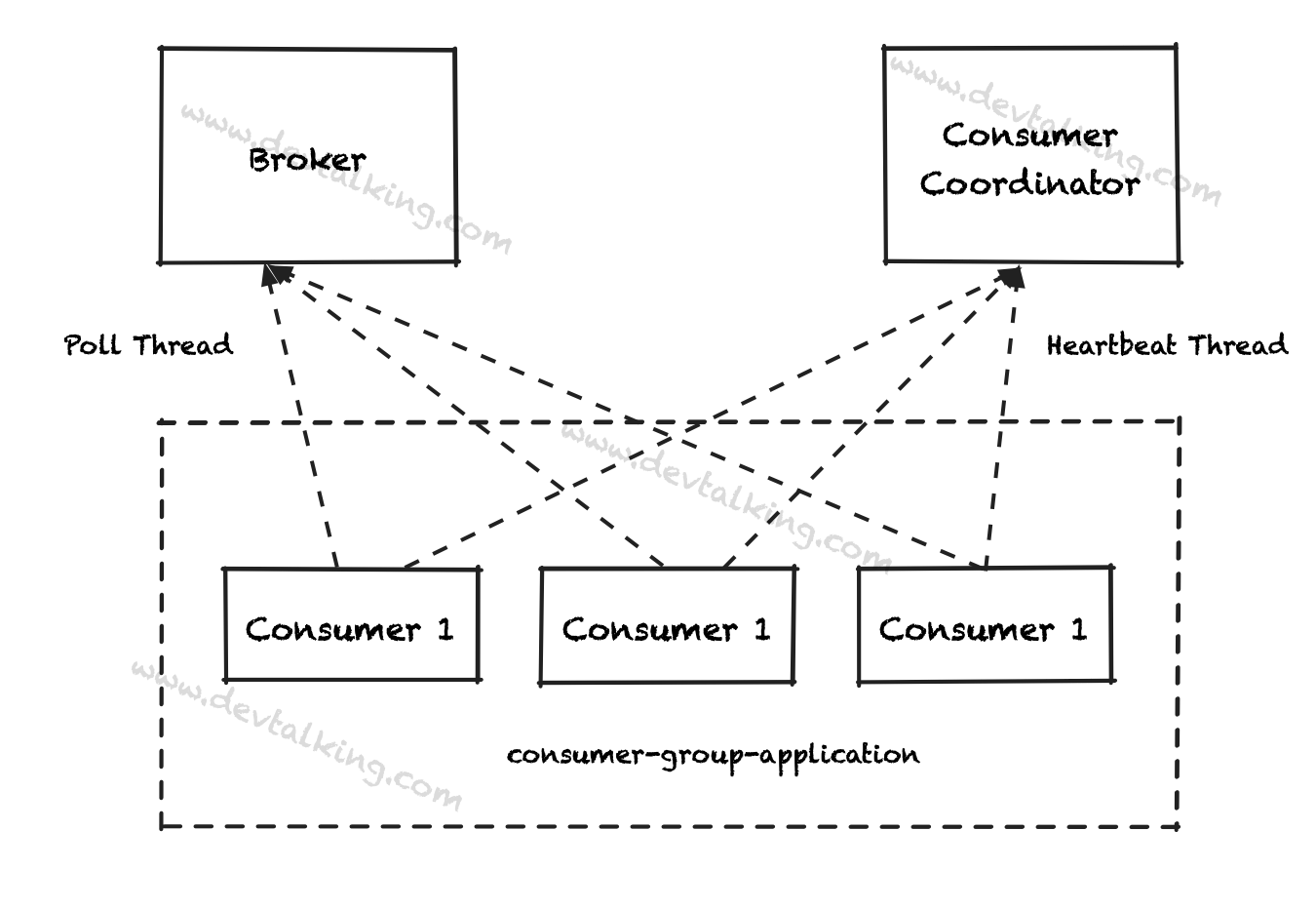
这里引出了两个参数:
seesion.timeout.ms:该参数的作用是Broker认为Consumer挂掉的持续时间。默认为10秒。也就是说Broker在10秒内没有收到Consumer的心跳信号,那么认为该Consumer已经挂掉了。heartbeat.interval.ms:该参数决定了Consumer发送心跳信号的间隔时间。默认为3秒。
总结一下前文介绍的Kafka核心概念。先上一张图总体概括:
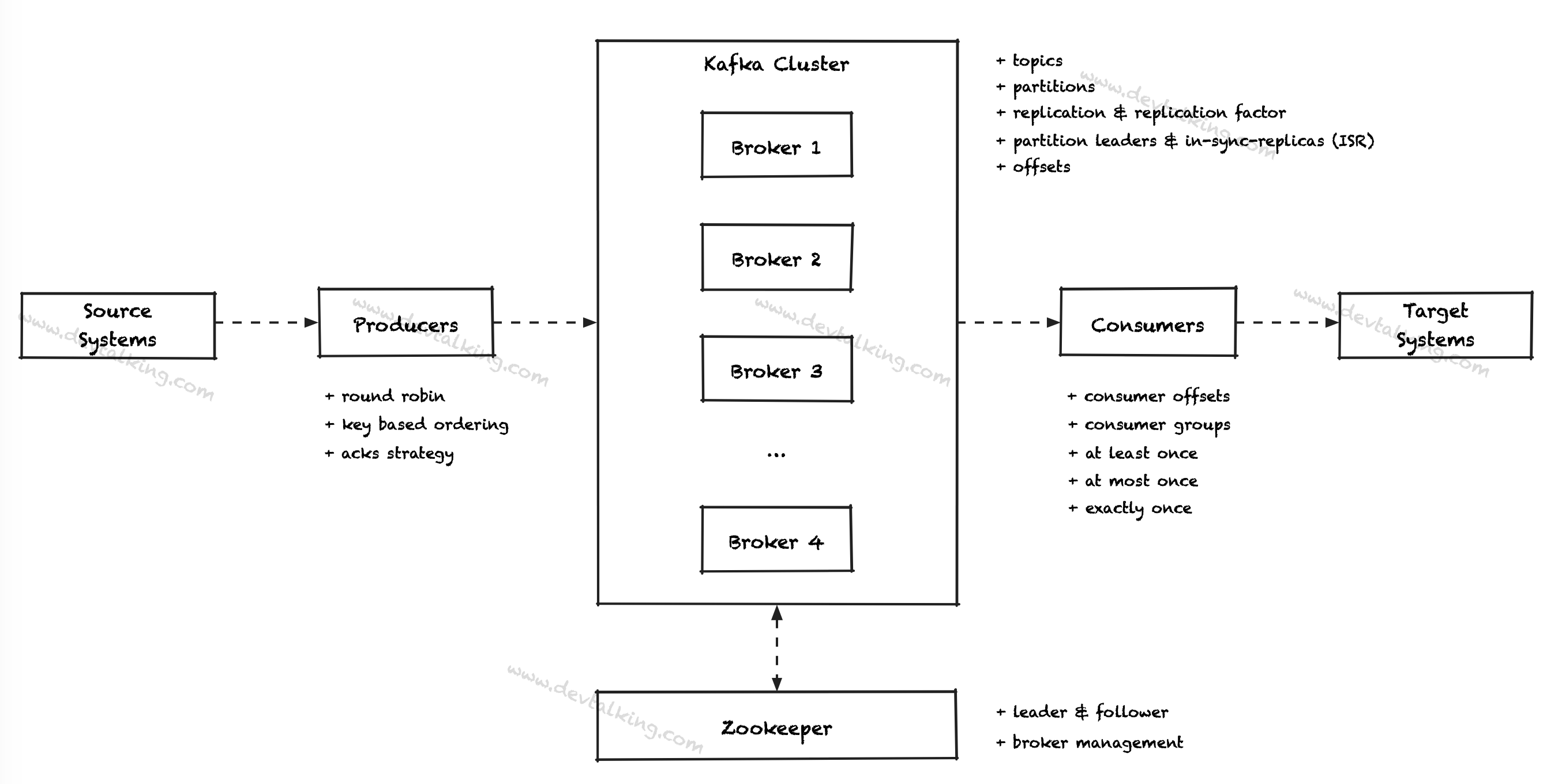
Producer
在Producer层面,我们了解了以下知识点:
- Producer发送Message到Broker默认采用轮询方式,除非显示的将Message带着Key。
- 如果希望Message根据某个字段发送至相同的Partition中,可以将Message带着Key发送。
- Producer有acks机制,关系到Message的完整性,以及整体MQ系统的整体性能(Message吞吐量)。
- Producer发送Message有重试机制。
- 在实际使用时,我们通常需要考虑幂等Producer,以确保不会有业务上的错误。
- Message压缩和批量发送有助于提高Message传输性能。
Broker
在Broker层面,我们了解了以下知识点:
- Partition是以文件夹的形式存储在Broker中的。
- Partition有Replication的概念,可以确保Message的完整性。
- Partition有Leader和ISR的概念。
- Partition中Message存储的方式。
- Partition中清理Message的策略。
Consumer
在Consumer层面,我们了解了以下知识点:
- Consumer有组的概念,Consumer Group和Consumer获取Topic中数据的方式。
- Consumer提交Offset的策略,关系到Consumer断点续传的方式。
- Consumer如何控制获取Topic中Message的速率。
- Consumer如何重制Offset。
最后我们再明确一下有哪些是Kafka提供的保障,或者说是我们不能,也不应该违背的原则:
- Message写入Topic-Partition的顺序严格按照Producer发送Message的顺序。
- Consumer从Topic-Partition读Message的顺序严格按照Partition中Message的Offset顺序。
- 如果Partition的Replication Factor是N,那么可以允许有N-1个Broker挂掉,而且Kafka可以正常运转。
- 只要Topic的Partition的数量恒定,那么带有指定Key的Message会始终写入该Key对应的Partition。
- 如果你想给Kafka集群中的某个Topic发送数据,你只需要连接Kafka集群中的一个Broker以及给定Topic名称既可。不用考虑Partition、Replication等等的问题。
总结
前面五个章节阐述了什么是MQ系统,然后基于这个大的框架介绍了Kafka系统中的核心模块,以及这些核心模块中的核心知识点。之后的章节主要就是实践部分,包括如何使用Kafka CLI、搭建Zookeeper、单机Kakfa、集群Kafka等。希望能给小伙伴们带来帮助。