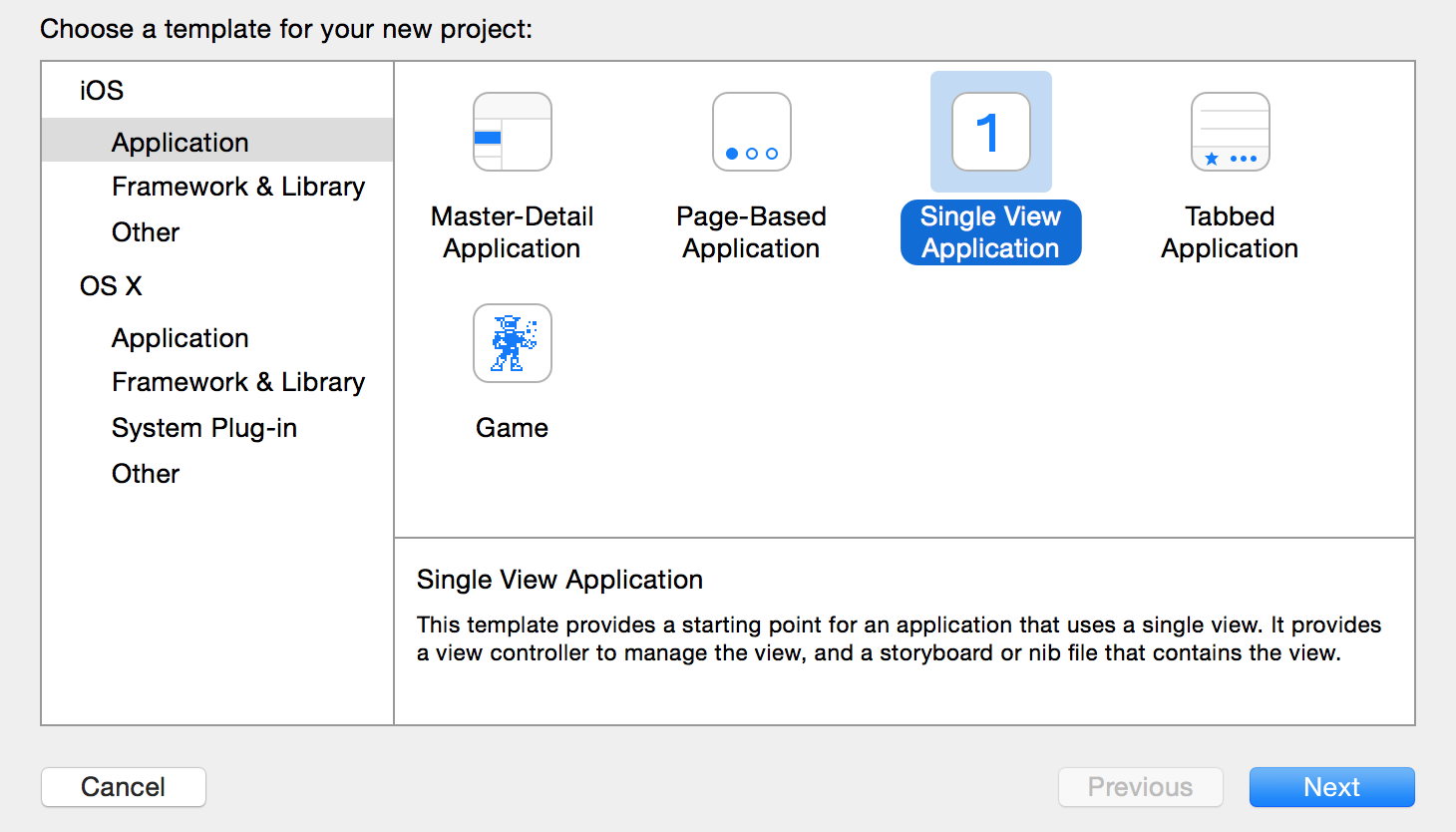
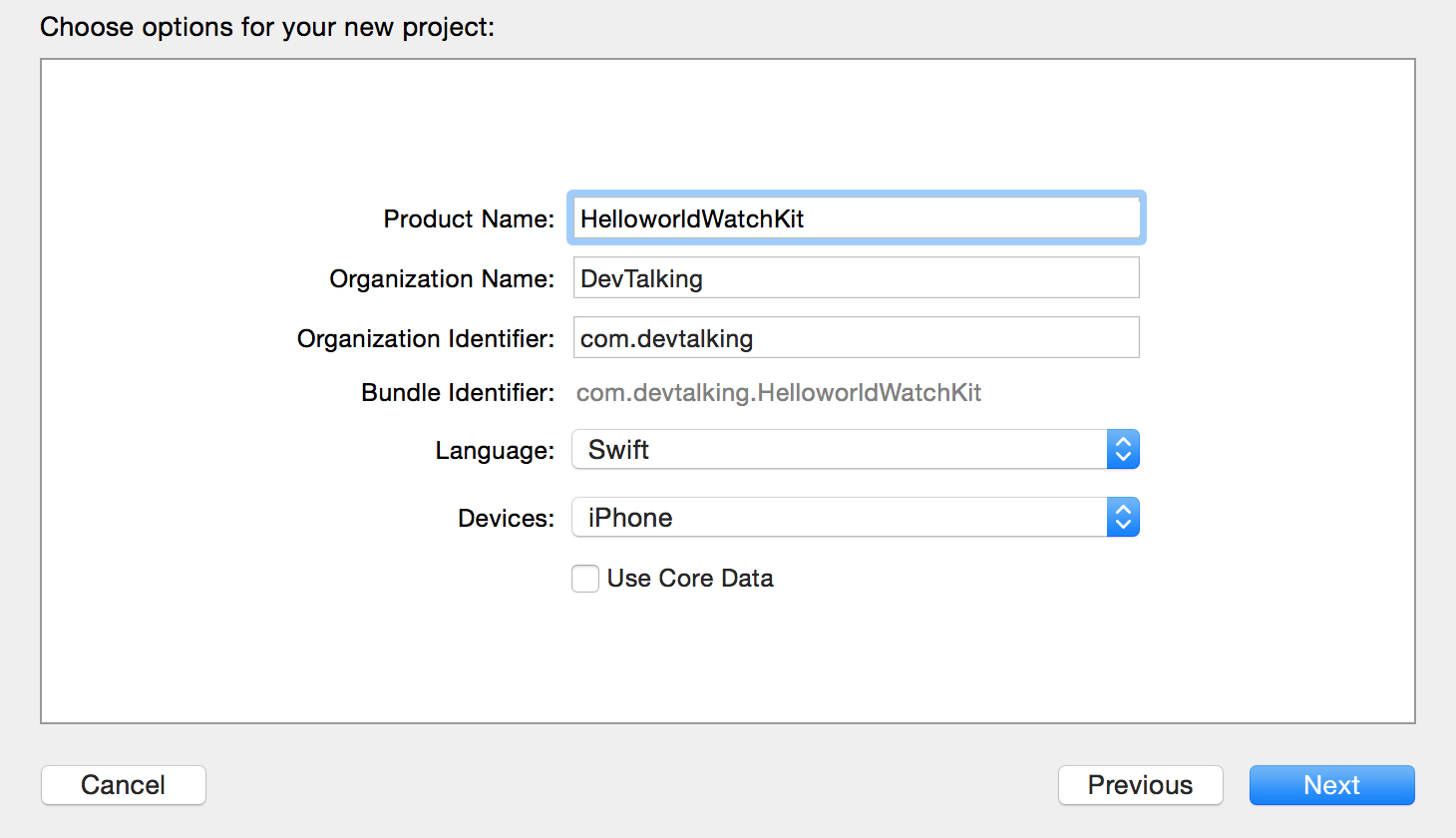
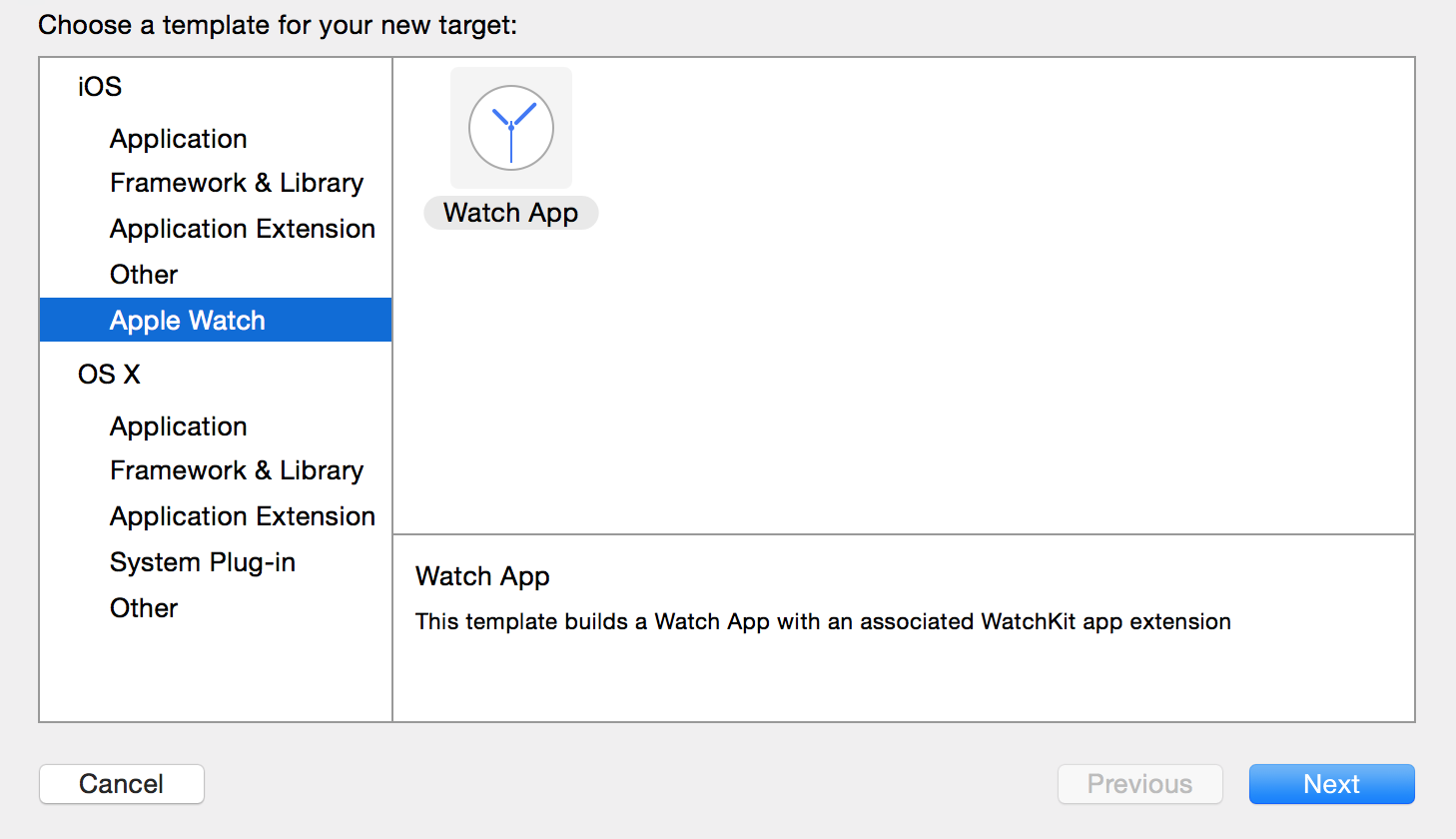
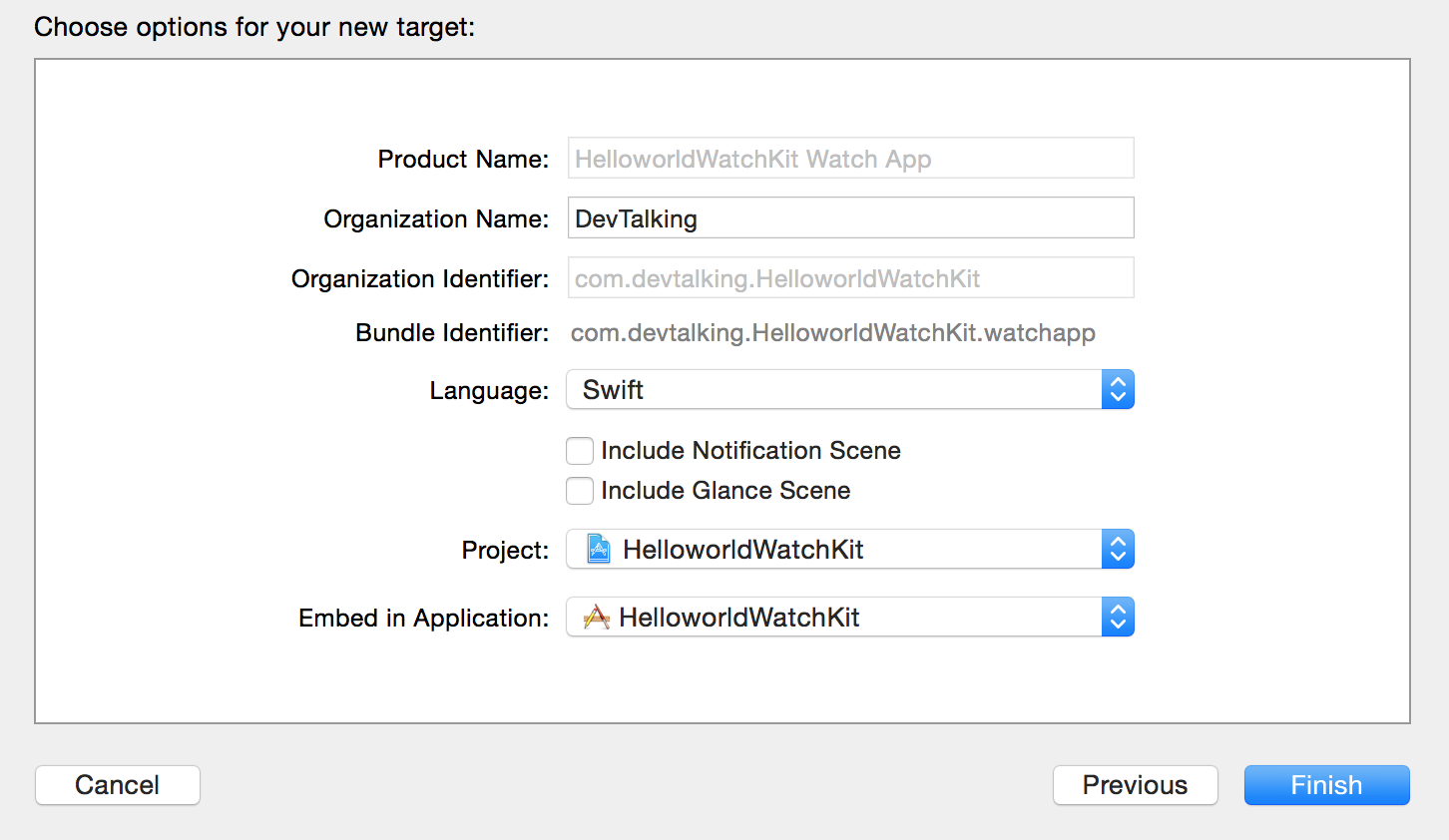
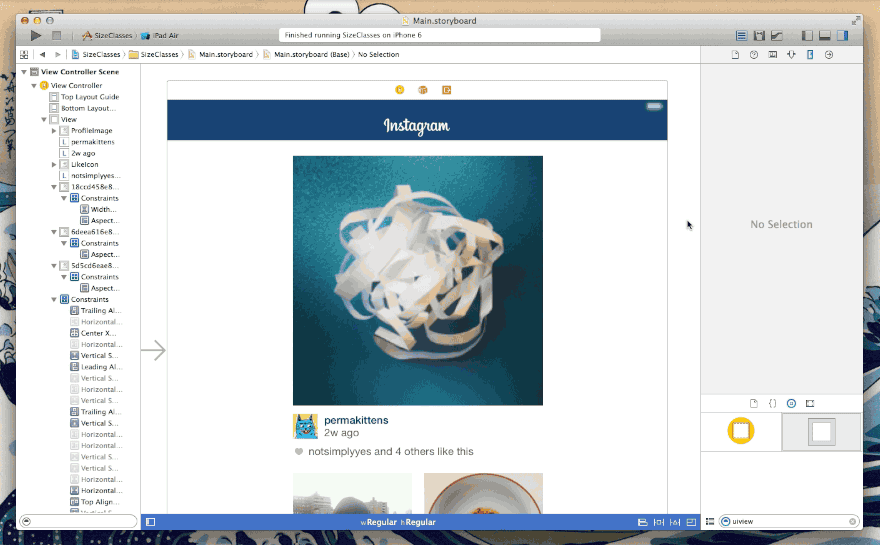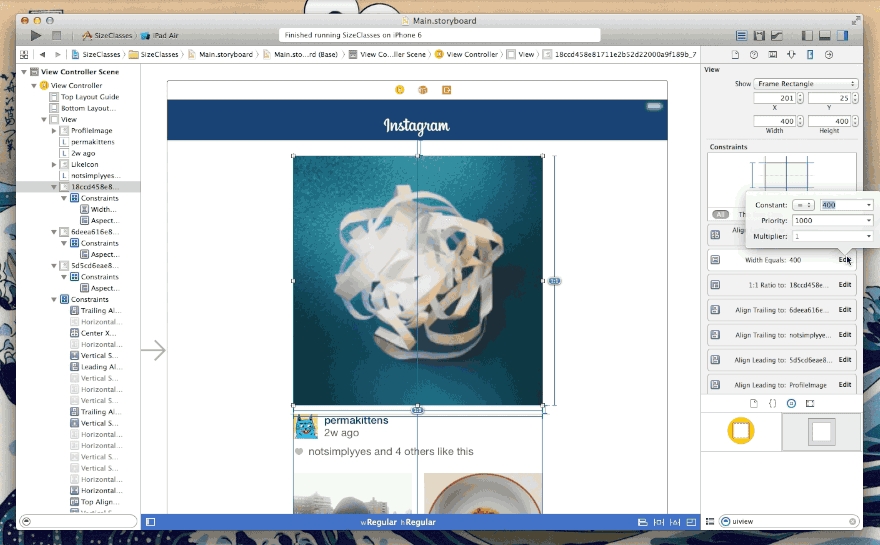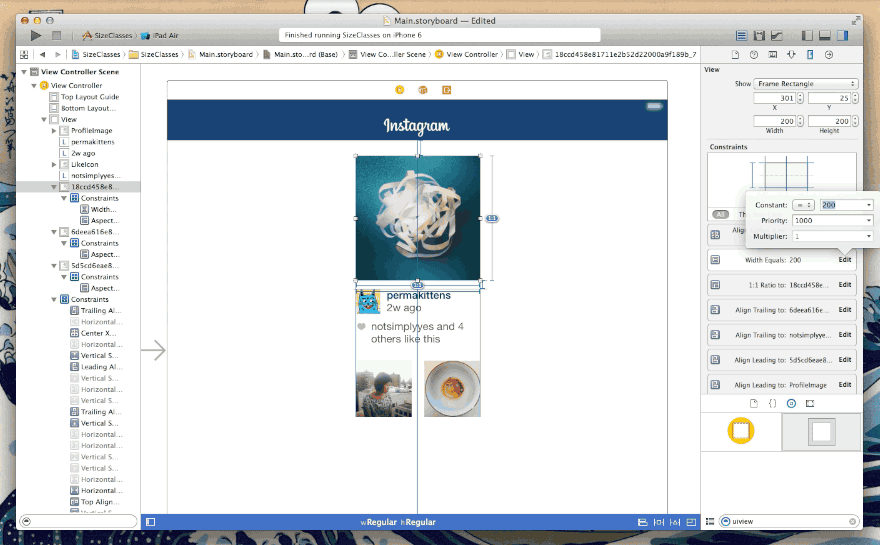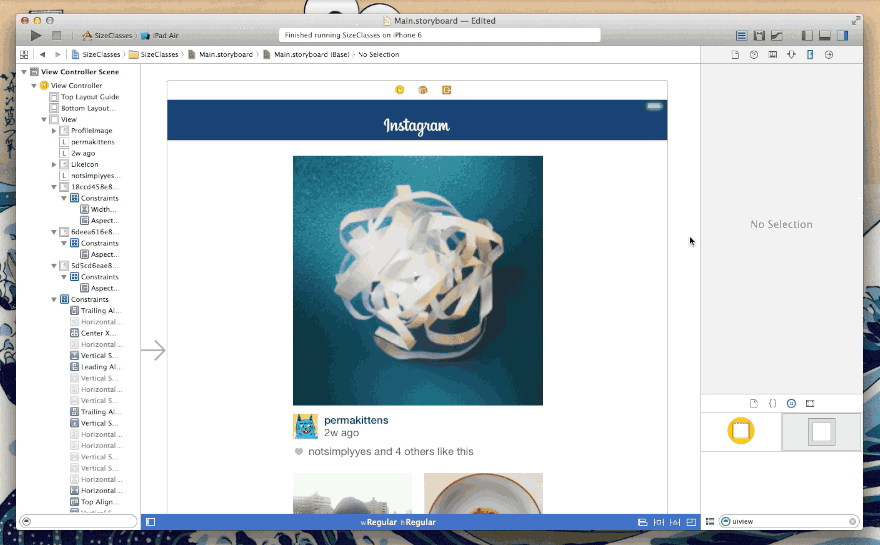
由于Apple近几年在iOS系统的不断改进过程中添加了许多新的特性和功能,这使得iOS系统对文本的渲染能力有了大大的提升。在iOS7中我们就已经能感觉到在文本渲染方面有了很大改进和提升。现在iOS8发布了,在文本渲染方面在延续了之前强大功能的基础上,又提升了其易用性。简单纵观iOS文本渲染的发展史,你也许对目前文本渲染的强大能有更深刻的体会。
在iOS6之前,使用web视图渲染文本是当时最为容易的一种方式,因为它能较为有效的处理混合编排的文本,比如有粗体字、斜体字、有颜色的字等。
2012年,iOS6在UIKit框架中添加一些支持字符串编辑或渲染的控件。这使得在渲染文本时,使用web视图不再是唯一的选择了。并且在文本排版方面不用再依赖通过HTML布局这种方式了。
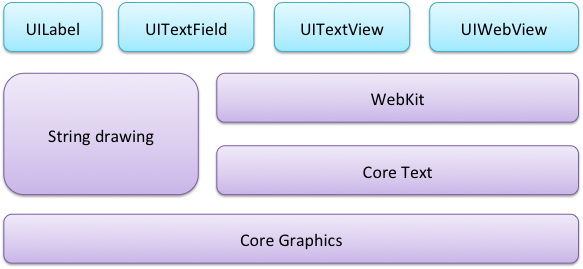
在iOS6中,UIKit中支持字符串编辑和渲染的控件是同时基于WebKit和Core Graphic的String drawing函数开发出的,整个如下图所示:
注意:在这张图上有没有让你疑惑的地方呢?没错,UITextView是基于WebKit框架的。实际上,UIKit中与文本相关的这些控件在底层还是使用HTML渲染的。没有深入研究过相关框架的开发者是不太容易察觉这一点的。
尽管iOS6中提供的这些文本控件在实际开发中的确带来了不少便利,但是当遇到复杂的布局、多行混合渲染等这种高级应用场景时,这些控件就显得捉襟见肘了,此时虽然Core Text是相对底层而且用法繁复的框架,但使用它来解决问题仍是唯一可以选择的方法。
直到iOS7的问世,这种窘境得以改善。随着扁平化的设计思路,iOS的UI拚弃了沿用多年的拟物化风格,将重点和关注点集中在排版工艺上。比如UIButton在iOS7中去掉了整个外边框和阴影,只留下了按钮文字。所以Apple在iOS7中加入了用于文本编排和渲染的Text Kit 框架就不足为奇了。
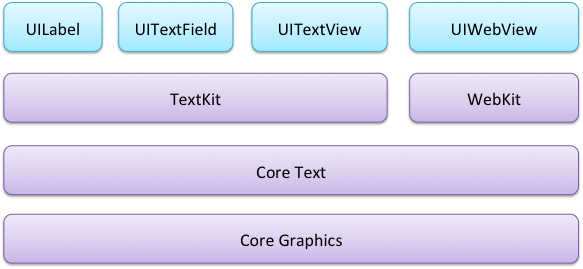
在iOS7中关于文本渲染的控件及框架结构就比较清晰和合理了。因为所有UIKit中的文本控件都基于Text Kit框架,而不像iOS6中还有基于Web Kit框架的:
Text Kit在继承了Core Text所有强大功能的基础上,将功能封装为面向对象的API,让开发者们都乐开了花。
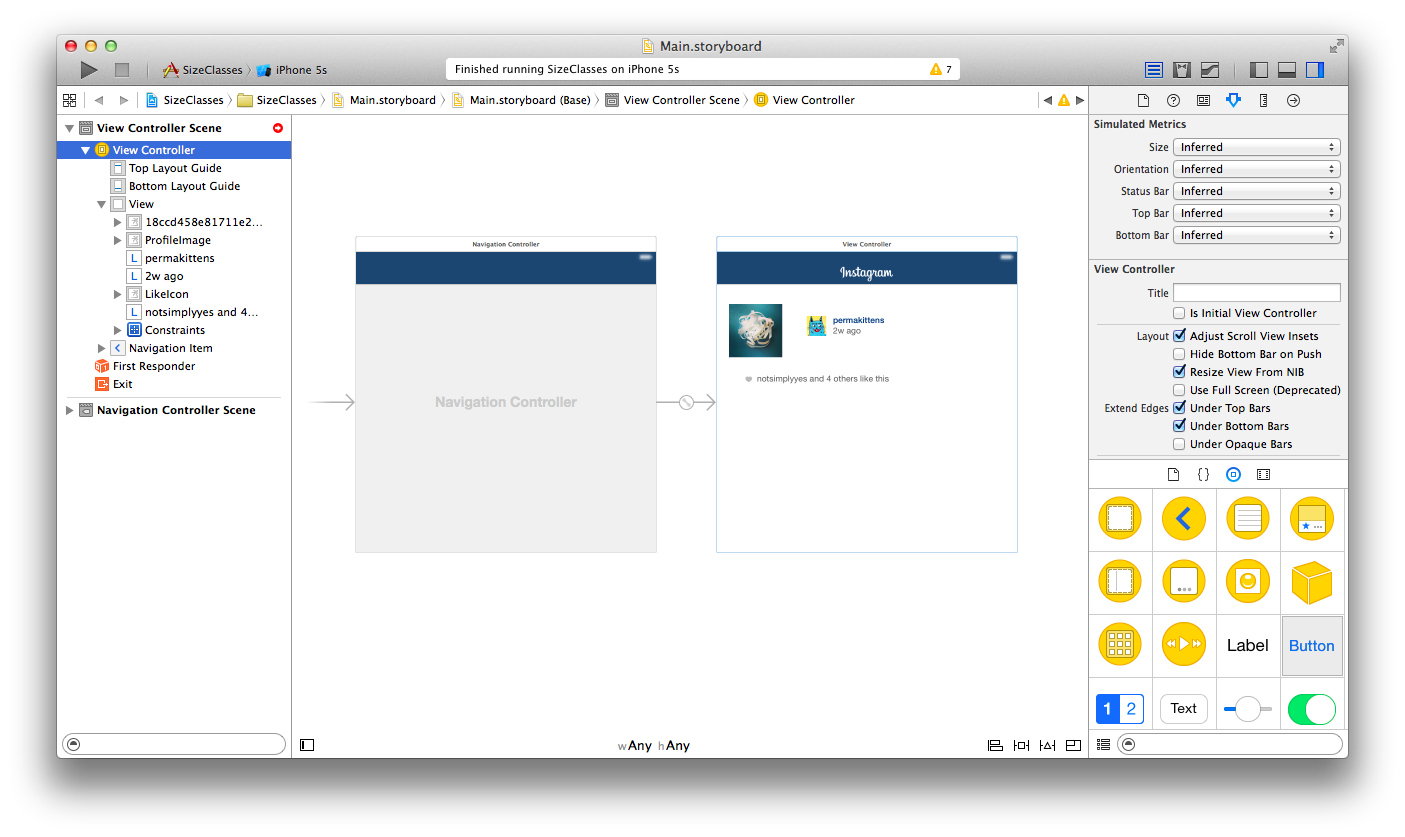
在这篇教程中,你要去探索Text Kit的各种功能特性,并且你要创建一个简单的但又功能丰富的iPhone笔记应用。
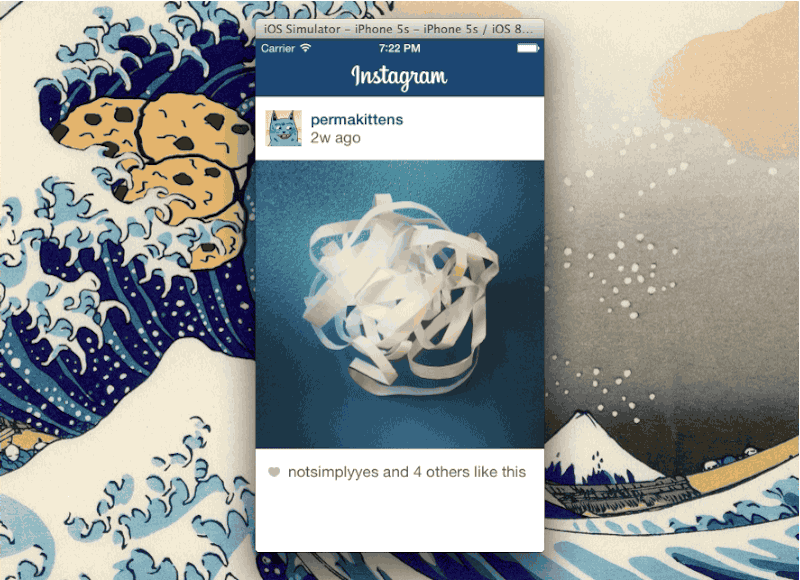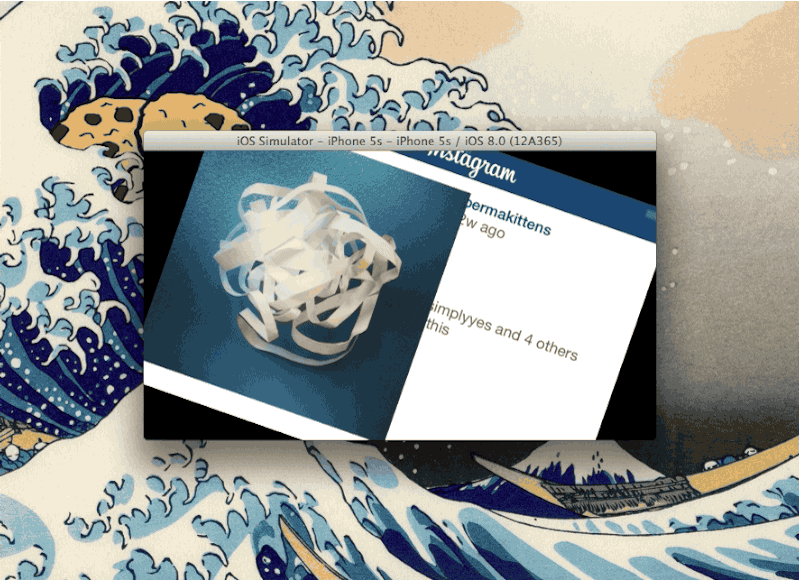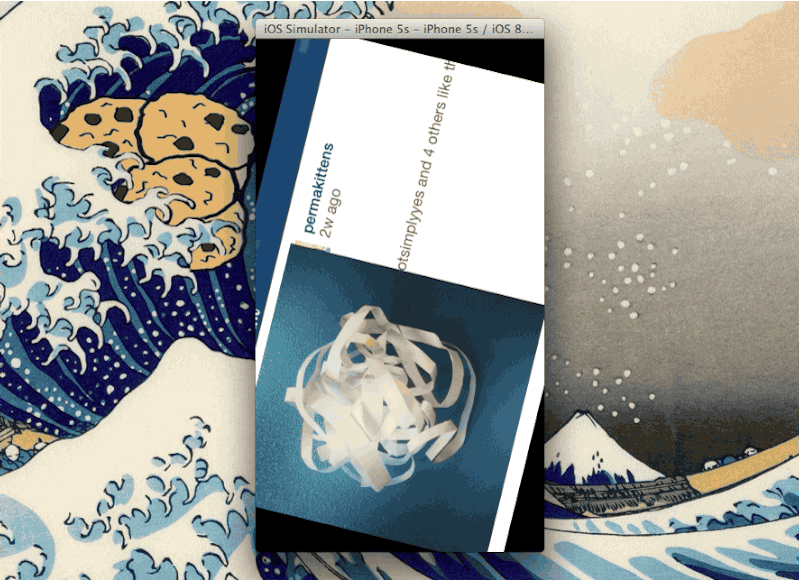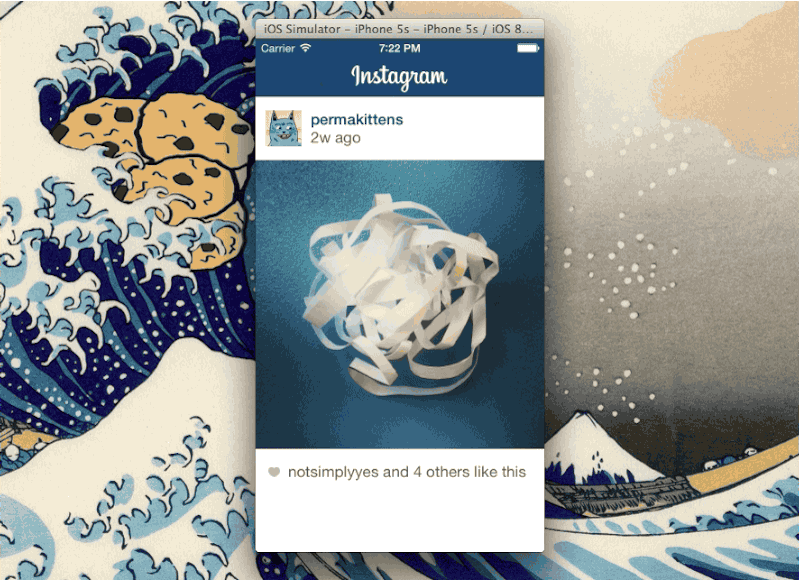
本教程包含一个初始的项目,里面含有事先创建好的UI部分,以便使同学们只关注于Text Kit的部分。在这里可以下载该项目 。下载完成后解压并在Xcode中打开项目,编译运行后你会看到如下的界面:
该示例应用创建了一个初始的数组用于存放笔记实例,然后在TableViewController中将其渲染出来,当你点击选择某条笔记时,Storyboard和segue会捕获到你的行为,然后处理视图转换的先关工作,使你看到该条笔记的详细信息。
Dynamic Type Dynamic Type 是iOS7中给我们的开发带来变化最多的特性之一,它的作用是让应用中的字体大小遵循你设置的字体大小和粗细。
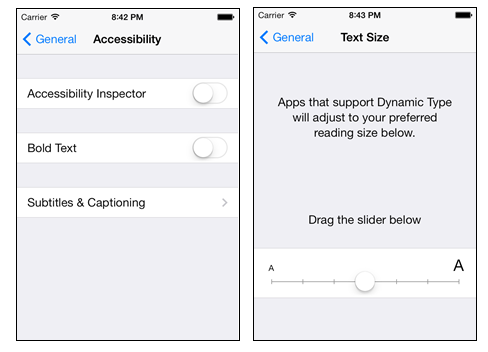
在iOS7中,打开设置,可以在 通用/辅助功能(General/Accessibility) 和 通用/字体大小(General/Text Size) 中查看和设置系统中应用显示字体的属性:
在iOS8中,打开设置,可以在 通用/辅助功能/更大字体(General/Accessibility/Larger Text) 查看Dynamic Type的文本尺寸。
不管是增加文字粗细还是改变文字大小,在支持Dynamic Type的应用中这都能给用户带来极大的便利,增加了文字的可读性。
为了让应用支持Dynamic Type,你需要设置文本遵循某一风格 ,而不是明确的指定文本的字体名称和大小。在iOS7中已经为UIFont增加了一个新的方法preferredFontForTextStyle,它的作用是给创建出一个由用户在设置中根据自身需要设定的风格的字体。
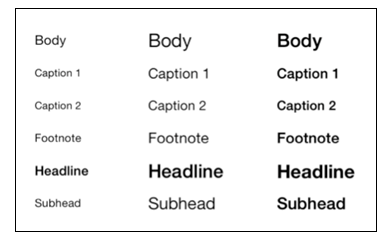
下表中展示了六种不同字体样式的不同大小和粗细程度:
表中最左边的字体是用户可选择的最小的字体,中间是可选择的最大的字体,最右边是选择了辅助功能中给字体加粗后的样式。
最基本的功能支持 实现动态文本的基本功能还是相对较简单的。应用中的字体不再是一个明确的字体,而是需要请求一个特殊的字体样式。在运行时,应用会根据用户在设置应用中对字体的设置以及请求到的字体样式中选择一个合适的字体样式。
到了iOS8,Apple让实现Dynamic Type变得比iOS7更加容易了。尤其是TableView中的默认Label自动支持Dynamic Type,这个很赞!但是如果还想适配iOS7的话那就要在TableView中使用自定义的Label了。所以首先同学们要学会如何在iOS7中处理Dynamic Type,然后你就会发现到了iOS8后,生活是多么美好,晴空万里,没有雾霾!
为什么iOS7是优秀的系统,而iOS8是趋近完美的系统 该教程中初始项目的设置和配置是基于iOS8的。在我们开始学习之前,先编译运行应用,然后尝试改变默认的文本字体大小,多试几次不同的字体大小。你会发现不光是字体大小变了,TableView列表的Cell高度也相应发生了改变。但是你对这个项目还没动过一根手指。同时你也应该发现了点击选择一条笔记后,该笔的详细信息的文本字体却没有发生变化。
但在iOS7中我们的确还要做一些额外的事,没有十全十美的事应该指的就是这个吧。如果你的编译环境是iOS7或iOS8(确保你使用的Xcode版本是6),那么本教程的绝大部分内容都是没问题的。现在我们需要将Xcode的编译环境设置为iOS7已经选择合适的iOS模拟器(iPhone5s)。如果你不打算支持iOS8之前的系统,那么你可以直接使用iOS8的编译环境。
现在咱们在iOS7下编译运行应用,然后重复之前修改字体的操作,你会发现什么?没错,发现了悲剧。应用中的字体会忽略你对字体的设置,根本不起作用。所以,同学们必须要做点什么让Dynamic Type在iOS7跑起来。
打开NoteEditorViewController.swift ,在viewDidLoad方法中添加如下代码:
textView.font = UIFont .preferredFontForTextStyle(UIFontTextStyleBody )
这里需要注意的是你并没有给textView.font设置具体的字体,比如Helvetica Neue之类。相反,你只是请求了一个适合主体文本的字体样式UIFontTextStyleBody。
然后打开NotesListViewController.swift ,在tableView(_:cellForRowAtIndexPath:)方法的return语句后添加如下代码:
cell.textLabel?.font = UIFont .preferredFontForTextStyle(UIFontTextStyleHeadline )
你依然没有给字体具体的类型,而是请求了一个合适的字体样式。
使用语义接近的字体样式名称,比如UIFontTextStyleSubHeadline,可以避免在代码中对字体样式使用硬编码,并确保你的应用中的文本信息能正确的响应用户的设置。
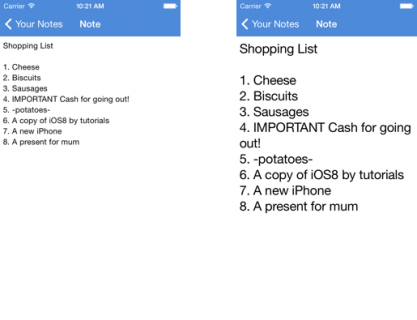
现在再编译和运行应用,你会发现TableView和笔记详细信息页面中的文本字体都发生了变化。下面的截图是设置不同字体大小后的笔记详细信息页面:
目前看起来一起都很完美,但是细心的读者可能会发现这种解决方法只能解决一半的问题。让我们回到设置应用然后再次更改字体大小,然后我们通过后台程序回到我们的笔记应用中,我们发现了什么?没错,文本字体没有响应我们刚才的设置从而发生变化。
我相信我们的用户是不会允许这种事情发生的。又一个挑战出现了,让我们来看看如何解决这个问题。
即时响应字体设置 打开NoteEditorViewController.swift,在viewDidLoad方法中添加如下代码:
NSNotificationCenter .defaultCenter().addObserver(self , selector: "preferredContentSizeChanged:" , name: UIContentSizeCategoryDidChangeNotification , object: nil )
上面这段代码的作用是将我们的NodeEditorViewController注册到通知中心里,当字体发生改变时会通知NodeEditorViewController中的preferredContentSizeChanged方法。
我们再来看看preferredContentSizeChanged方法:
func preferredContentSizeChanged (notification: NSNotification) textView.font = UIFont .preferredFontForTextStyle(UIFontTextStyleBody ) }
在这个方法中我们就可以改变文本的字体样式了。
注意:这里你可能会有疑惑,已经更改过字体样式了,为什么这里再次请求样式的时候还是UIFontTextStyleBody呢?当用户更改完字体样式后,你需要通过preferredFontForTextStyle方法重新请求一次字体样式,该方法的参数只代表文本的类型和所在位置,比如是Body里的还是Head中的等,所以UIFont.preferredFontForTextStyle(UIFontTextStyleBody)的意思就是请求类型和位置在Body中显示文本的字体样式,每次请求都是获取最新一次设置的字体样式。
打开NotesListViewController.swift,重写viewDidLoad方法:
override func viewDidLoad () super .viewDidLoad() NSNotificationCenter .defaultCenter().addObserver(self , selector: "preferredContentSizeChanged:" , name: UIContentSizeCategoryDidChangeNotification , object: nil ) }
同学们应该注意到了,我们刚才添加的方法和NoteEditorViewController.swift中添加的方法一样。没错,给NSNotificationCenter注册的方法是相同的,但是preferredContentSizeChanged方法会有点区别。
然后在NotesListViewController.swift中再添加preferredContentSizeChanged方法:
func preferredContentSizeChanged (notification: NSNotification) tableView.reloadData() }
上面这段代码的作用是让Tableview重新加载可见的Cell,在更新时就会触发preferredFontForTextStyle()方法,将新设置的字体样式应用到Tableview的Cell中。
再次编译运行应用,设置字体样式,然后看看我们的应用有没有正确的响应你的设置。
使Cell高度自适应 响应字体设置这部分到目前为止我们已经处理完了,效果也不错,但是当你把字体设置为一个足够小的,或者最小的字体时,在TableView中看起来就不怎么好看了,因为Cell的高度没有变化,而字体很小,所以看起来很不美观,比如下面左侧的截图一样:
这个问题是iOS7中在Dynamic Type中比较坑爹的一个问题。想要使你的应用在不同字体样式下都显示的比较完美,你必须要让Cell的高度根据字体样式的大小做出相应的调整。虽然Auto Layout能帮你解决大部分布局适配上的问题,但在这个问题上,它就比较无力了,这得需要你自己去解决了。
解决这个问题的原理很简单,就是让TableView的Cell高度根据字体样式的大小进行改变。那么可以通过实现UITextViewDelegate的tableView(_:heightForRowAtIndexPath:)方法来解决该问题。
在NotesListViewController.swift中加入如下代码:
let label: UILabel = { let temporaryLabel = UILabel (frame: CGRect (x: 0 , y: 0 , width: Int .max , height: Int .max )) temporaryLabel.text = "test" return temporaryLabel }() override func tableView (tableView: UITableView!, heightForRowAtIndexPath indexPath: NSIndexPath!) CGFloat { label.font = UIFont .preferredFontForTextStyle(UIFontTextStyleHeadline ) label.sizeToFit() return label.frame.height * 1.7 }
上面的代码中,首先创建了一个UILabel的实例,用于计算TableView中Cell的高度,也就是这个UILabel的高度就是Cell的高度,然后在tableView(_:heightForRowAtIndexPath:)方法中设置该UILabel的字体样式,调用sizeToFit方法使Label的高度适配字体的高度,最后将Label的高度返回,也就相当于将Cell的高度设置为Label的高度了。这里需要注意的是当调用完sizeToFit方法后,Label与它里面字体之间几乎没有上下间隔,所以我们在返回高度的时候乘以一个上下间隔的比例系数。
再次编译和运行你的应用,多更改几次字体样式,你会看到Cell的高度随着字体样式也进行着调整:
给文本添加印刷效果 给文本添加一点高亮和阴影来达到文本像嵌入纸张的那种印刷效果。
打开NotesListViewController.swift用下面的代码替换tableView(_:cellForRowAtIndexPath:)方法:
override func tableView (tableView: UITableView!, cellForRowAtIndexPath indexPath: NSIndexPath!) UITableViewCell ? { let cell = tableView.dequeueReusableCellWithIdentifier("Cell" , forIndexPath: indexPath) as UITableViewCell let note = notes[indexPath.row] let font = UIFont .preferredFontForTextStyle(UIFontTextStyleHeadline ) let textColor = UIColor (red: 0.175 , green: 0.458 , blue: 0.831 , alpha: 1 ) let attributes = [ NSForegroundColorAttributeName : textColor, NSFontAttributeName : font, NSTextEffectAttributeName : NSTextEffectLetterpressStyle ] let attributedString = NSAttributedString (string: note.title, attributes: attributes) cell.textLabel?.attributedText = attributedString return cell }
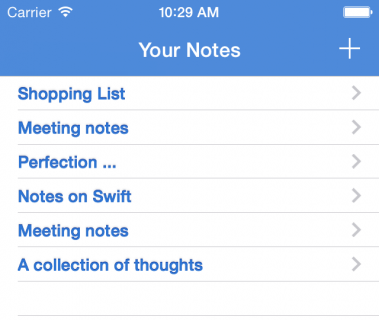
上面的代码给TableView的Cell中的文本添加了颜色和NSTextEffectLetterpressStyle文字样式。
编译运行应用,你会看到更加立体的文本:
这种印刷效果虽然只是一种较为细微的效果,但这并不代表你就能滥用这种效果,它虽然能使文本看起来有立体感,但是有可能会影响到文本的清晰度。
文本绕行排版 一般我们在常用的文本编辑器,比如Word中都能看到文本围绕图片或表格等其他元素的排版格式。TextKit也提供了能让文本按指定的路径排版或按一定形状排版的功能,叫做绕行路径。
下面我们希望在笔记详细页中添加一个圆形的视图,放在右上角,用于显示这篇笔记的创建时间。
当你创建完视图摆好位置后,你会发现这个圆形的视图会遮盖住笔记文本信息,所以我们需要给文本创建一个绕行路径来绕开这个圆形的视图。
添加圆形视图 打开NoteEditorViewController.swift,申明一个属性:
var timeView: TimeIndicatorView !
然后在viewDidLoad方法的最后添加如下代码:
timeView = TimeIndicatorView (date: note.timestamp) textView.addSubview(timeView)
创建一个timeView的示例,然后将它作为一个子视图添加到textView中。
刚才创建的视图需要合适的尺寸大小,你需要一种机制在ViewController绘制子视图调用updateSize方法来计算尺寸。
所以我们加入如下两个方法:
override func viewDidLayoutSubviews () updateTimeIndicatorFrame() } func updateTimeIndicatorFrame () timeView.updateSize() timeView.frame = CGRectOffset (timeView.frame, textView.frame.width - timeView.frame.width, 0 ) }
这里的viewDidLayoutSubviews方法会调用updateTimeIndicatorFrame方法,该方法会处理两件事,一个是调用updateSize方法设置timeView的尺寸,另一个是设置timeView的位置,使它处于textView的右上角。
之后每次当ViewController接收到文本字体样式更改的时候都会调用updateTimeIndicatorFrame方法,以便将timeView的尺寸和位置调整到合适的状态。所以我们更改一下preferredContentSizeChanged方法:
func preferredContentSizeChanged (notification: NSNotification) textView.font = UIFont .preferredFontForTextStyle(UIFontTextStyleBody ) updateTimeIndicatorFrame() }
现在编译运行应用,点击笔记条目进入详细信息页后你就会在右上角看到一个显示创建时间的圆形视图:
你可以在设置中改变字体样式,显示创建日期的视图会根据字体样式自动调整到合适的大小。
但是你们会发现还有一些美中不足的地方,那就是日期视图把笔记文本信息给遮住了,幸运的是TextKit提供的文本绕行路径能帮我们解决这个问题。
创建绕行路径 打开TimeIndicatorView.swift,看看curvePathWithOrigin方法,日期视图在填充渲染背景色的时候会调用该方法,但是你可以通过该方法来决定文本的绕行路径,该方法会自己计算视图的贝塞尔曲线,也就相当于是文本的绕行路径了。
打开NoteEditorViewController.swift,在updateTimeIndicatorFrame方法末尾中添加如下两行代码:
let exclusionPath = timeView.curvePathWithOrigin(timeView.center)textView.textContainer.exclusionPaths = [exclusionPath]
上面的代码通过日期视图的curvePathWithOrigin方法基于贝塞尔曲线计算出绕行路径,然后放在数组中赋值给textView.textContainter.exclusionPaths属性。这里要注意的是绕行路径的起点和坐标与文本信息是相对位置。
编译运行应用,现在你就可以看到文本信息都绕开了日期视图:
这个简单的示例只是体现出了绕行路径强大功能的冰山一角,从上面的代码中你可能也注意到了,绕行路径是放在数组中进行赋值的,所以这就意味着每个容器,不管是文本容器还是其他容器都可以被设置多个绕行路径。
除此之外,绕行路径可以随着你的想法变得简单或者复杂,你甚至可以让文本围绕着星星形状或者蝴蝶形状排版。
每当绕行路径发生改变时,文本容器就会通知布局管理器,你可以让绕行路径进行动态的改变,比如从星星形状的路径变成蝴蝶形状的路径,此时文本容器也会动态的改变排版。但是这样做会得不偿失,因为用户在阅读的时候看到文字动来动去,估计会砸了手机!
未完待续……
原文地址:Text Kit Tutorial in Swift